The Measurability Trap
Karpathy mapped which jobs AI could disrupt. Anthropic measured which ones it actually is. The gap tells us everything about where we are, and the fault line isn't skill or education. It's whether your output can be measured.
Three things happened in the same week in March 2026 that, taken together, tell a more complete story about AI and jobs than any one of them does alone. Andrej Karpathy published a map of which jobs AI could disrupt. Anthropic published data on which jobs it actually is disrupting. And Christian Catalini named the pattern that explains both: it’s not about skill or education. It’s about whether your output can be measured.
I want to walk through all three, because the gap between what AI can do and what it’s doing is where the real story lives.
Karpathy’s contribution is a treemap of AI exposure across 342 US occupations. Each rectangle is a job. The area is employment size. The color is AI exposure on a 0-10 scale, scored by Gemini Flash against Bureau of Labor Statistics data. A 10 means the job’s core tasks are fully within reach of current AI. A 0 means they’re not.
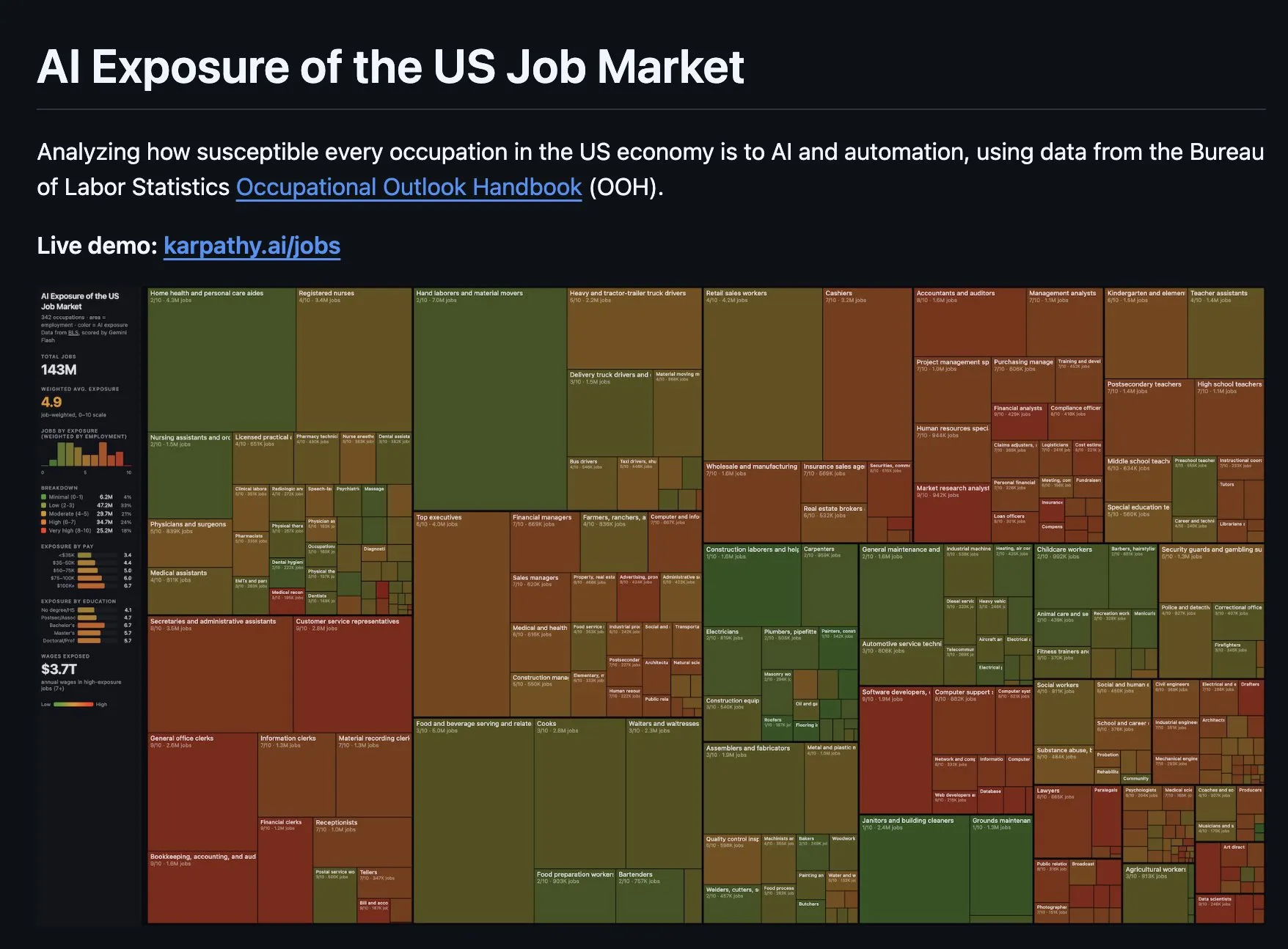 Karpathy’s AI Exposure treemap. The interactive version at karpathy.ai/jobs has since been taken down.
Karpathy’s AI Exposure treemap. The interactive version at karpathy.ai/jobs has since been taken down.
342 occupations scored 0-10. Rectangle area = employment size. Color = AI exposure. Green = safe. Red = exposed.
143 million jobs. Weighted average exposure of 4.9, nearly dead center. $3.7 trillion in annual wages in the high-exposure zone. Green rectangles (construction, healthcare, trucking) sprawl across the top. Red and brown ones (accountants, analysts, management consultants, teachers) cluster to the right. Physical work is safe. Measurable work is exposed.
But exposure scores tell you what AI could theoretically do to a job. They don’t tell you what’s actually happening. An occupation can score 9/10 on exposure and still have zero real-world AI adoption. That distinction turns out to matter a lot.
The map vs the territory
Anthropic researchers Maxim Massenkoff and Peter McCrory published “Labor Market Impacts of AI” in March 2026. Their key contribution is a metric called “observed exposure.” Most AI labor studies score jobs based on whether AI could do the tasks (theoretical feasibility). Massenkoff and McCrory added a second layer: whether AI is actually doing them, using real Claude usage data cross-referenced against the O*NET database of ~800 occupations.
The idea is simple. For each task in a job, they ask: can an LLM double human performance on this task? Score it 1.0 if the LLM can do it alone, 0.5 if it needs tools, 0 if it’s infeasible. That gives you the theoretical ceiling. Then they look at actual Claude conversations to measure how much of that ceiling is being used in practice. The gap between the two numbers is the story.
And the gap is huge.
Computer and Math occupations have a 94% theoretical feasibility score, meaning almost all of their tasks could be done or significantly aided by AI. But only 33% of those tasks are actually being done with AI today. That’s a 3x gap. Business and Finance? Same 94% ceiling, roughly 28% actual. Legal? 89% feasible, 18% actual. Architecture and Engineering? 85% feasible, about 15% real. The further you go from software and data work, the wider the gap gets.
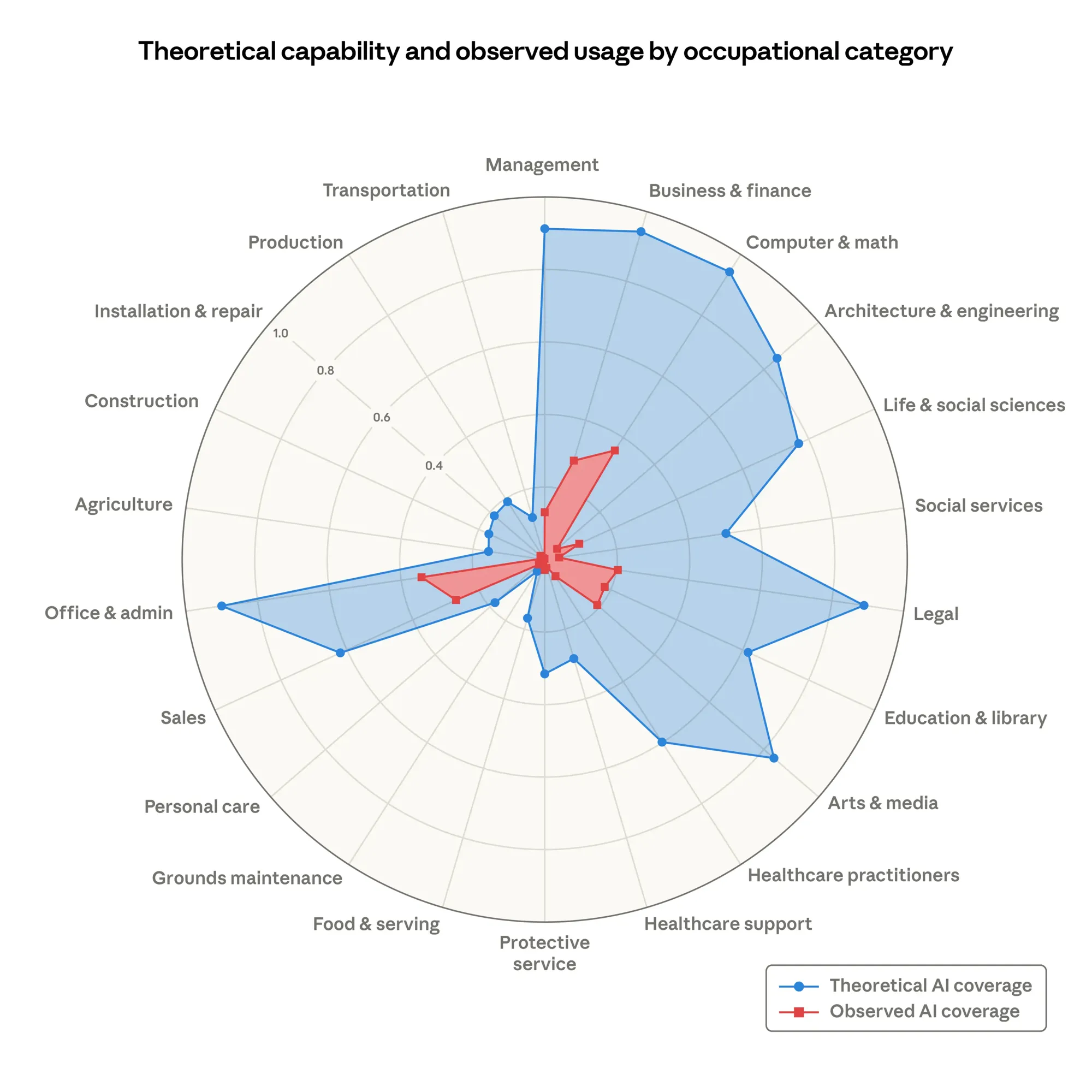 Theoretical AI coverage (blue) vs observed AI coverage (red) across occupational categories. Source: Anthropic, “Labor Market Impacts of AI” (March 2026).
Theoretical AI coverage (blue) vs observed AI coverage (red) across occupational categories. Source: Anthropic, “Labor Market Impacts of AI” (March 2026).
One number puts this in perspective: 97% of Claude usage is on tasks that are theoretically feasible. When people do use AI, they use it for things it can actually do. The problem isn’t that AI tries and fails. The problem is that most people and organizations haven’t started using it yet. Capability is not the bottleneck. Adoption is.
 Interactive
Interactive The fault line isn’t skill
Christian Catalini put it well the same week:
Skill-biased technical change is dead. What its successor looks like: measurability-biased technical change. The fault line is no longer how educated you are. It’s whether your output can be measured. If it can, it will be industrialized. No exceptions.
Once you see it this way, the Karpathy treemap makes more sense. It’s not sorting jobs by skill level or education. It’s sorting them by how measurable the output is.
Consider the extremes. Medical transcription scores a perfect 10: audio goes in, text comes out, and you can objectively verify whether the transcription is correct. The entire job is a measurable transformation. Construction laborers score near zero because their work requires physical presence, spatial judgment, and moment-to-moment adaptation that resists quantification. You can’t specify the output of “build this wall in this weather on this terrain” in a way an LLM can act on.
Most jobs sit somewhere in between. A financial analyst’s job is part measurable execution (build the model, run the numbers, draft the report) and part non-measurable judgment (decide which assumptions matter, read the client, present a recommendation under uncertainty). The measurable part is exposed. The non-measurable part, for now, is not.
What’s exposed isn’t “strategy” or “research.” It’s the measurable execution bundled inside those roles: the drafts, the models, the analyses. The economy built a wage premium around that bundle. AI unbundles it.
This is the core of Catalini’s argument. For decades, the economy paid a premium for jobs that bundled judgment and execution together. A lawyer’s value wasn’t just knowing the law; it was also doing the legal research, drafting the briefs, reviewing the documents. AI can do the research and drafting. It can’t (yet) exercise judgment about which arguments will land with a specific judge. The bundle is coming apart, and the wage premium attached to the execution half is what’s at risk.
Who’s actually exposed
Previous waves of automation hit factory floors and routine clerical work. The assumption was always that education was the shield: the more skilled and credentialed you were, the safer your job. AI inverts that.
Anthropic’s data shows the highly exposed workers earn 47% more on average than unexposed workers. 17.4% hold graduate degrees, compared to 4.5% in the unexposed group. They tend to be older and more female. This is the opposite of the usual automation story.
Why? Because educated, well-paid knowledge workers are the ones whose jobs have the most measurable execution bundled in. A management consultant earning $200K spends a large portion of their time on tasks that have clear inputs and outputs: build the deck, analyze the data, draft the recommendation memo. A home health aide earning $35K spends their time on tasks that are hard to specify: read the patient’s mood, adjust care in real time, navigate a family’s emotional dynamics. The consultant is more exposed precisely because their work is more measurable.
This creates a strange two-speed dynamic in wages. PwC’s 2025 data shows jobs requiring AI skills now command a 56% wage premium, up from 25% the prior year. So the premium for wielding AI is doubling. But the premium for doing what AI does, the measurable execution work, is under pressure. If you can use AI to do the analysis yourself, why pay someone else to do it?
The entry-level problem
If AI exposure is concentrated among well-paid, experienced knowledge workers, you’d expect to see them losing jobs. They’re not. Anthropic found no systematic increase in unemployment for highly exposed workers since ChatGPT launched. Using Current Population Survey data going back to 2016, they looked for divergence between exposed and unexposed occupation groups. There isn’t one. Their confidence intervals are tight enough that they could detect a 1-percentage-point shift if it existed.
That’s the headline. The buried finding is more troubling.
Erik Brynjolfsson at Stanford and collaborators at MIT analyzed millions of ADP payroll records (real hiring and firing data, not surveys) and found a 13% relative decline in employment for early-career workers ages 22-25 in the most AI-exposed occupations since late 2022. Workers over 30 in those same jobs? Up 6-13%.
Same occupation. Same AI exposure score. Opposite outcomes depending on age.
The mechanism makes sense once you think about it. A senior financial analyst knows which assumptions matter, which data sources to trust, and what the client actually needs. Give them an AI tool that can build models and draft reports, and they become faster. They produce more with the same effort. But a junior analyst’s value proposition used to be doing that model-building and report-drafting. That was how they learned the judgment that would eventually make them senior. AI compresses the learning period by removing the repetitive work, but it also removes the on-ramp.
Think of it like apprenticeship. A junior developer used to learn by writing boilerplate, fixing simple bugs, and doing code reviews. Those tasks taught them the codebase, the patterns, and the standards. If AI handles the boilerplate and fixes the simple bugs, the junior has fewer ways to build context. The experienced developer doesn’t need that context; they already have it.
70% of occupations in the lowest AI exposure quintile saw rising early-career employment. Less than 50% in the highest exposure quintile did. The signal is concentrated in exactly the jobs where measurable execution used to be the training ground.
Five tensions in the data
The numbers keep contradicting each other. I don’t think that means the data is bad. I think it means we’re in a genuinely weird transitional moment where multiple things are true simultaneously.
The capability-adoption gap. 60-94% of knowledge work is theoretically automatable, yet actual job displacement is near zero. This is the central finding from the Anthropic study: the theoretical ceiling is high, but real-world adoption is a fraction of it. Firms are slow to change workflows. Regulatory environments create friction. Individual workers haven’t been trained. The disruption potential is real, but the disruption itself is lagging behind by years.
The productivity paradox. Anthropic’s own data shows a 30% median productivity gain in specific, localized use cases where management actually measured AI impact. Individual workers consistently report getting more done. Yet Goldman Sachs chief economist Jan Hatzius says AI contributed “basically zero” to US economic growth in 2025. The most likely explanation is that adoption is still too limited to move economy-wide numbers. The gains are real but concentrated in pockets. As adoption spreads (see the gap above), the macro signal should follow.
The age inversion. Experienced workers in AI-exposed jobs are thriving (+6-13%). Entry-level workers in the same jobs are declining (-13%). This isn’t contradictory once you understand the mechanism: AI is a leverage tool that amplifies existing skill, not a replacement for it. If you know what to verify, you move faster. If you were supposed to learn what to verify by doing the work AI now handles, you have a problem.
The augmentation-automation balance. In January 2026, Anthropic’s Economic Index showed augmentation (52%) overtaking automation (45%) as the primary use pattern. Workers are using AI to do more, not fewer of them doing it. This is a genuinely positive signal, but worth noting that the ratio flipped. In August 2025, automation was dominant. The balance is unstable, and as AI capabilities improve, it could shift again.
The growth contradiction. Even the most automatable jobs are showing net employment growth: +38% for high-exposure roles, +65% for low-exposure. The WEF projects a net gain of 78 million jobs by 2030 (170 million created, 92 million displaced). Nobody’s shrinking yet. The question is whether this reflects genuine resilience or the fact that adoption hasn’t hit the tipping point.
What survives
Catalini frames the question worth sitting with:
Strip away the execution layer, and what’s left? That’s your moat. Or your problem.
What survives is the stuff that’s hard to measure. Deciding what question to ask in the first place. Navigating genuine uncertainty where there’s no clear right answer. Verifying whether an AI agent did the right thing when the output looks plausible but might be subtly wrong. Taking responsibility when it matters. These are the tasks that remain stubbornly human, because they require context, judgment, and accountability that can’t be specified in a prompt.
Concretely: a lawyer reviewing an AI-drafted brief needs to know whether the cited cases are real (hallucination check), whether the arguments align with this specific judge’s preferences (contextual judgment), and whether to stake their reputation on the filing (liability). A manager using AI-generated market analysis needs to know whether the assumptions match the company’s actual competitive position. A doctor reviewing an AI diagnostic suggestion needs to know the patient’s history, tolerance for risk, and family situation. The verification layer is where humans remain essential.
I keep coming back to the historical parallel. A decade ago, offshoring studies identified “roughly a quarter of US jobs as vulnerable.” Those predictions were mostly wrong. Massenkoff and McCrory themselves cite this: within a decade, the job-offshorability predictions “proved largely inaccurate.” The lesson is that theoretical exposure is a poor predictor of actual disruption.
But the Anthropic researchers also point out a key difference. This time, we have real usage telemetry. We know exactly which tasks AI is being used for, how adoption is growing, and where the gaps are. The distance between theory and reality is documented and measurable. And it’s closing.
The Anthropic study found that for every 10 percentage-point increase in observed AI coverage, BLS employment growth projections decrease by 0.6 percentage points through 2034. This relationship only appears with observed exposure, not theoretical exposure. The theoretical scores alone don’t predict employment changes. It’s the actual adoption that matters.
That’s not a cliff. It’s a slope. And we’re on it.
