HighStakes: where humans review, where AI handles the rest
Not all code changes carry the same risk. HighStakes scores every file by blast radius so your senior engineers review the code that matters and AI handles the rest.
Contents
Something quietly changed in how engineering teams work over the past year, and most leaders I talk to haven’t fully reckoned with it yet.
Your team adopted AI coding tools. Output went up. That part was visible. What wasn’t visible was the review burden that came with it.
Faros AI published their AI Engineering Report 2026, tracking telemetry from 22,000 developers across 4,000 teams. The numbers tell the story clearly. Code churn up 861%. Per-developer defect rate from 9% to 54%. Review duration up 441%. PRs merged with zero human review up 31%.
Separately, CodeRabbit’s analysis of 470 open-source PRs found AI-written code produces 1.7x more issues, with logic errors up 75% and security vulnerabilities 1.5 to 2x more common.
Meanwhile, GitClear’s productivity analysis showed that while AI users produce 4x raw output, actual durable productivity gains are far more modest. Code churn doubled from a 3.3% baseline to over 7%, meaning much of that output gets rewritten or deleted.
The gap between “4x output” and real productivity is review debt. Someone has to read all that generated code and decide whether to trust it. I wrote about this earlier in The Verification Bottleneck: AI scales execution to near-zero cost, but verifying that output stays biologically bounded. The bottleneck was never intelligence, it’s human verification bandwidth.
The bottleneck shifted, and most teams haven’t adjusted
Writing code used to be the expensive part. Now a junior developer with Copilot produces as much raw output as a senior one. But the ability to look at a diff and say “I understand what this does, and I’m confident it’s correct” is still a senior skill. That hasn’t been automated.
Your most experienced engineers are now spending the majority of their time reviewing code, not writing it. Their queue is 4x what it was a year ago. The common responses I see are hiring more reviewers or quietly skipping review on “safe-looking” PRs. The first is expensive and slow. The second is dangerous, and that 31% zero-review merge rate suggests it’s already widespread.
Not all code is equally dangerous
Addy Osmani put it well in his piece on Agentic Code Review: “The hard part of engineering moved from writing code to deciding whether to trust it.”
But here’s the thing most review processes miss. A bug in your auth middleware causes a security breach. A bug in your log formatter causes ugly timestamps. Both sit in the same review queue. Both get the same scrutiny.
Your senior engineers spend 45 minutes reviewing a PR that changes CSS colors because it’s queued behind the one that modifies token validation.
The fix isn’t more reviewers, it’s knowing which code is high-stakes and which isn’t.
I keep coming back to four questions when thinking about whether a file matters. Does it enforce a security boundary? Does it handle sensitive data? Could a failure here take down the service? Is this on a path your customers see?
A 10-line auth check can be more dangerous than a 500-line log parser. Complexity alone doesn’t tell you the risk; blast radius does.
Static analysis is necessary but not sufficient
Every code quality tool counts branches, measures cyclomatic complexity, and traces imports. These signals matter. A file with complexity 50 deserves more scrutiny than one with complexity 3. A file imported by 20 others has higher breakage potential than a leaf module.
But when I ran static analysis alone on a 382-file Rust and Python codebase, every file scored LOW. Zero differentiation. The tool could tell me that auth.rs has complexity 23. It could not tell me that auth.rs validates OIDC tokens, and a bug there means unauthorized access to every sandbox in the system.
Static analysis sees structure, not purpose. And purpose is what determines blast radius.
Combining static analysis with LLMs closes the gap
A recent paper on semantically-seeded impact analysis confirmed what I suspected. Pure structural analysis caps at 78.6% recall. Fusing semantic understanding with structural signals brings that to 100%. Neither approach works as well alone as they work together.
So instead of replacing static analysis, I added a second layer. Each source file gets sent to an LLM with one question: “if this code has a bug, what breaks?”
The LLM reads sandbox.py and returns: “Sandbox management failures could compromise isolation, leading to security breaches or service outage.” It scores 73, landing in the HIGH tier.
It reads theme.rs and says: “Breakage causes cosmetic terminal color issues.” Score of 6. LOW tier.
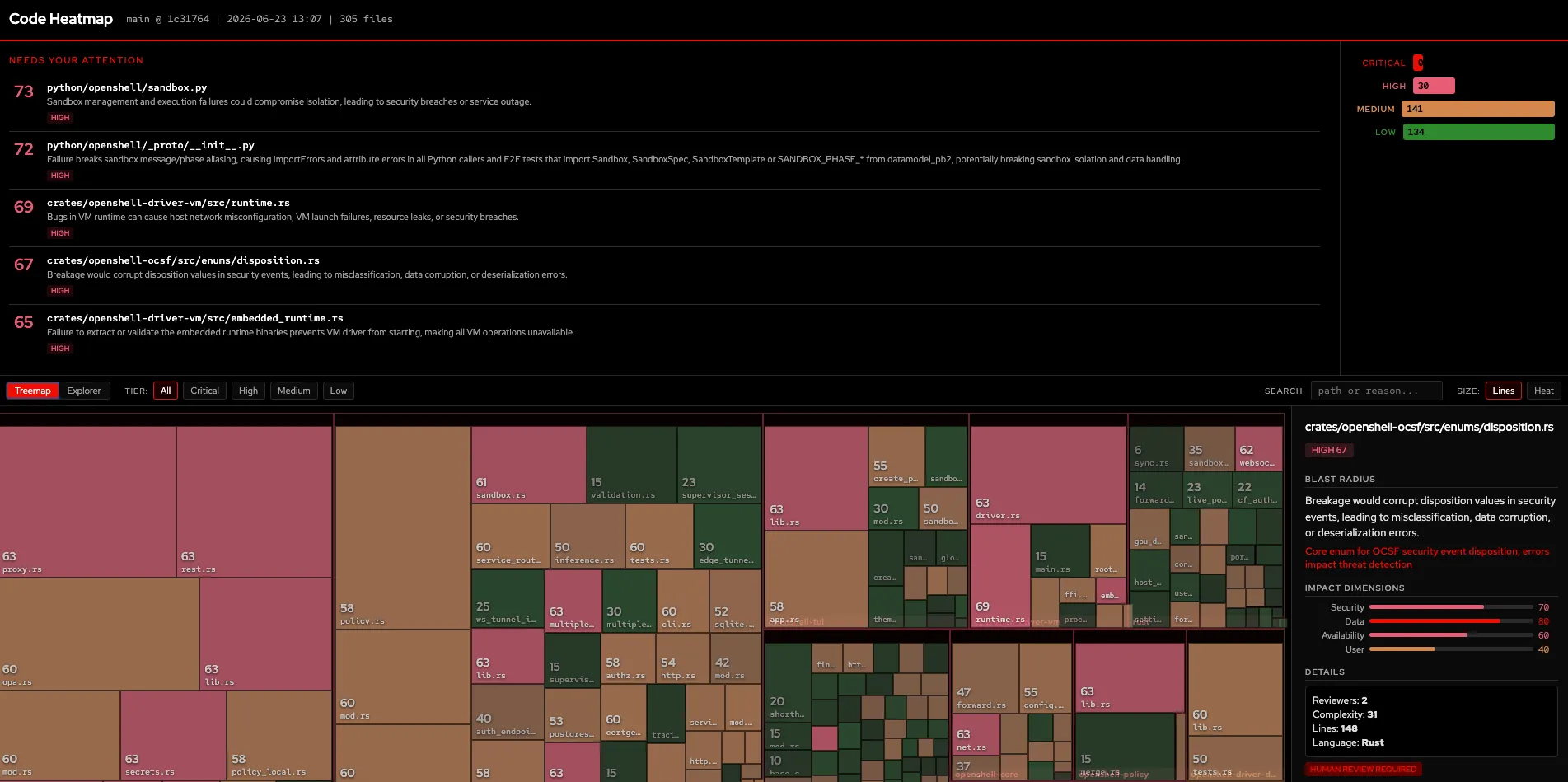
The LLM provides the semantic understanding. Static analysis provides complexity, dependency centrality, and change frequency. Git history adds churn data and incident correlation. Combined into a weighted score, the same 382-file repo that showed zero differentiation now breaks down into 30 HIGH, 141 MEDIUM, and 134 LOW files. Those 30 files are where your senior engineers should focus. The other 134 are safe for AI-assisted review or auto-merge.
Try it in 2 minutes
I built HighStakes to do this. It’s open source, a single Go binary, no dependencies beyond git.
go install github.com/zanetworker/highstakes/cmd/highstakes@latest
export OPENROUTER_API_KEY="sk-or-..."
cd /path/to/your/repo
highstakes init && highstakes analyzeThat’s it. It scans every source file, sends it to an LLM for blast radius assessment, combines with static analysis and git history, and gives you a score per file.
You need Go installed and an API key from OpenRouter, which is free to sign up and pay-per-use. You can also point it at any OpenAI-compatible API directly, whether that’s DeepSeek, OpenAI, or even a local Ollama instance. If you want to skip the LLM entirely, --no-llm gives you static-only analysis for free, though with less accuracy.
First analysis of a 500-file repo costs about $0.15. After that, only changed files get re-assessed, so ongoing cost is near zero.
What you get
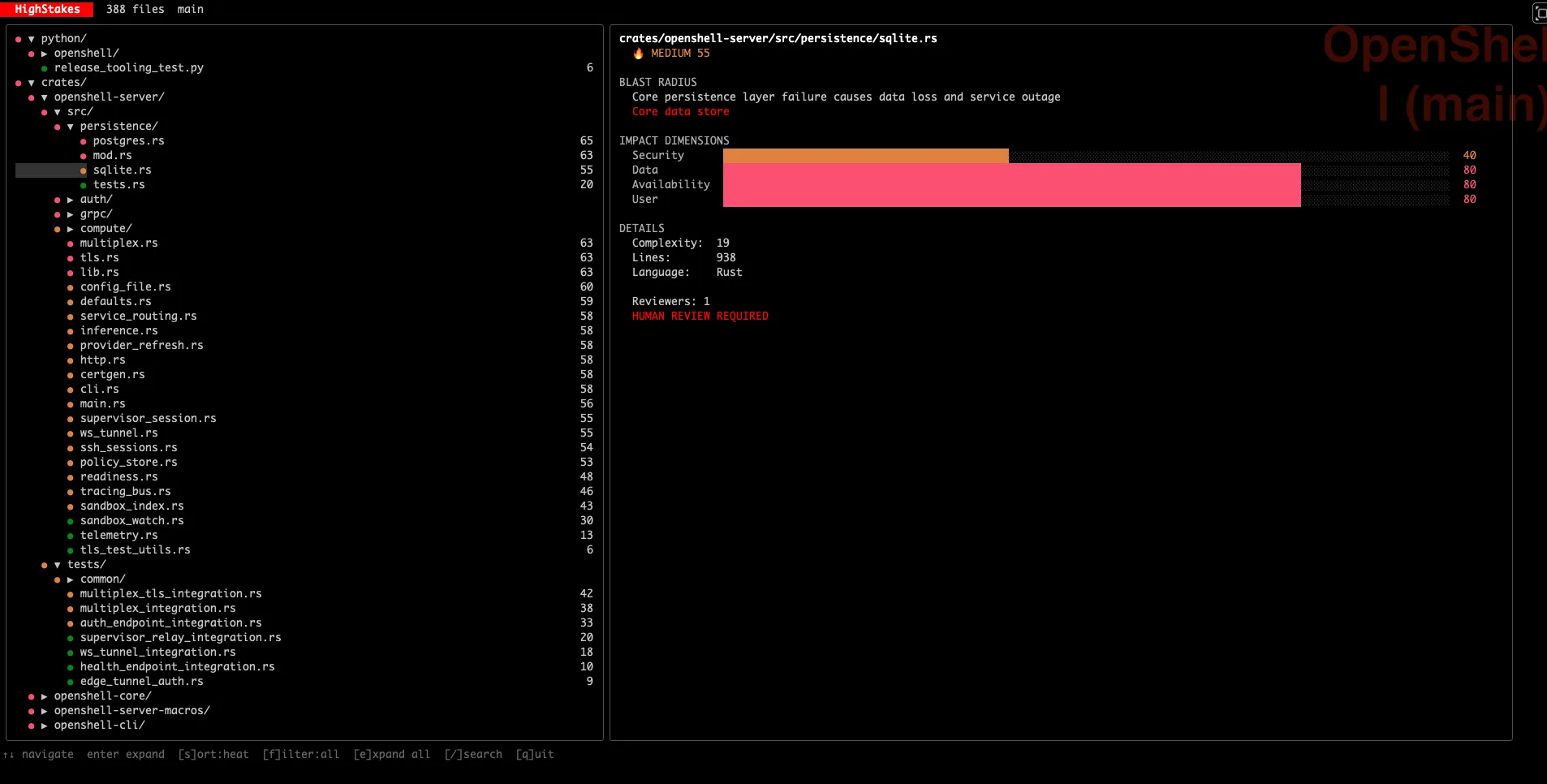
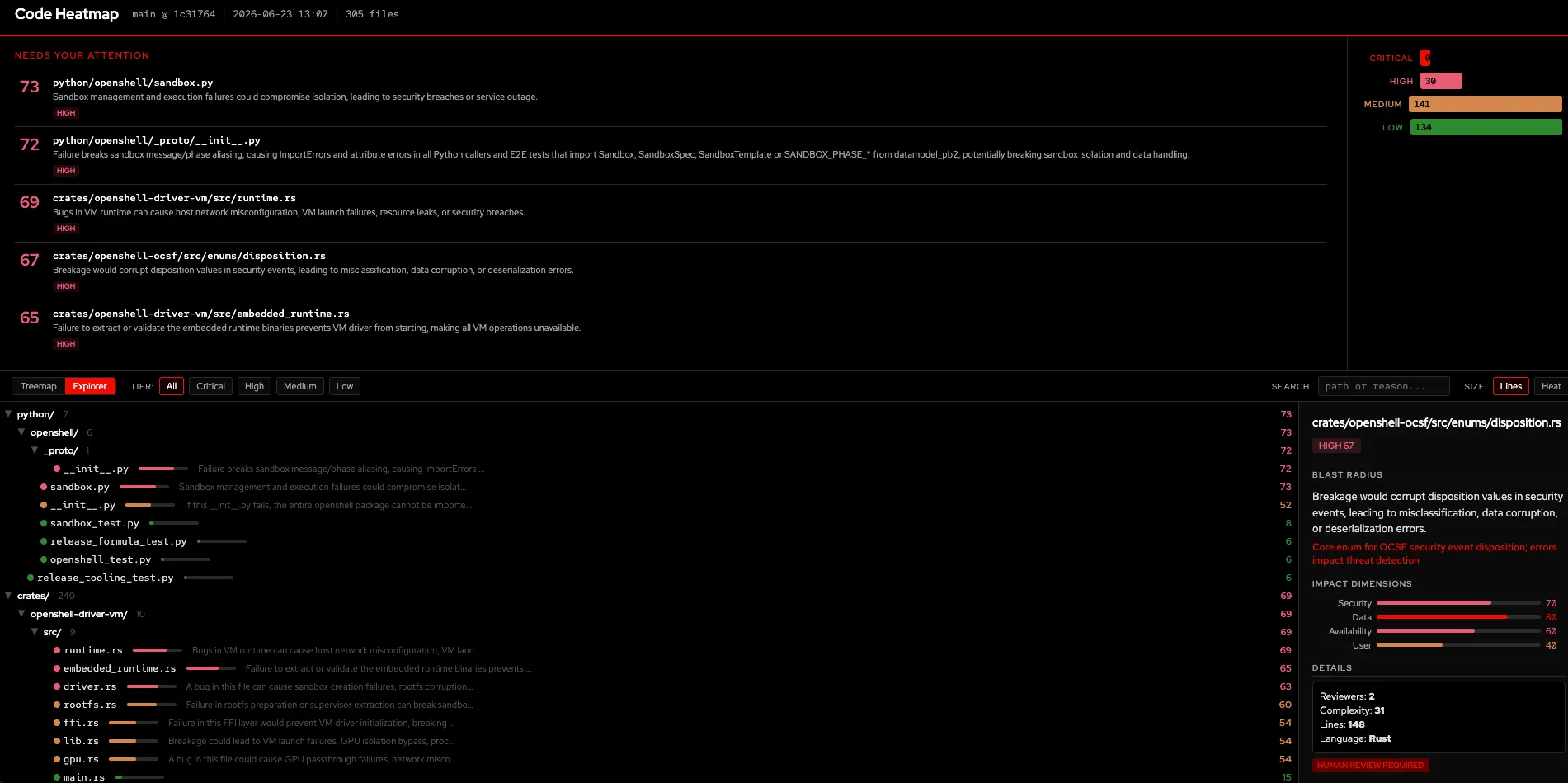
Every file in your repo gets a blast radius summary that explains why it matters, not just a number. You see scores across four impact dimensions: security, data, availability, and user impact. And you get concrete review requirements that tell you how many reviewers are needed, whether a security scan should run, and whether auto-merge is safe.
Three ways to explore the results:
An interactive treemap where the big red blocks are the files that need your attention first:
A terminal TUI with colored tier indicators, blast radius detail panel, and keyboard navigation:
A file explorer with collapsible directory tree, heat bars, and reasoning inline:
Or machine-readable JSON for CI:
highstakes list --tier high --jsonThe real value is in CI
When someone opens a PR, highstakes checks which files changed and posts a comment.
HIGH: 2 files need senior review
| File | Score | Tier |
|---|---|---|
| src/auth/oidc.rs | 63 | HIGH |
| src/sandbox/proxy.rs | 63 | HIGH |
| src/tui/theme.rs | 6 | LOW |
Review: 2 reviewers (senior), auto-merge blocked
You can gate merges. If a PR touches a HIGH or CRITICAL file, the pipeline fails until a senior reviewer approves. LOW-tier PRs sail through with AI review only.
This isn’t replacing human review, it’s routing it. The senior engineer who reviewed 20 PRs a day now reviews the 5 that actually need them.
The math
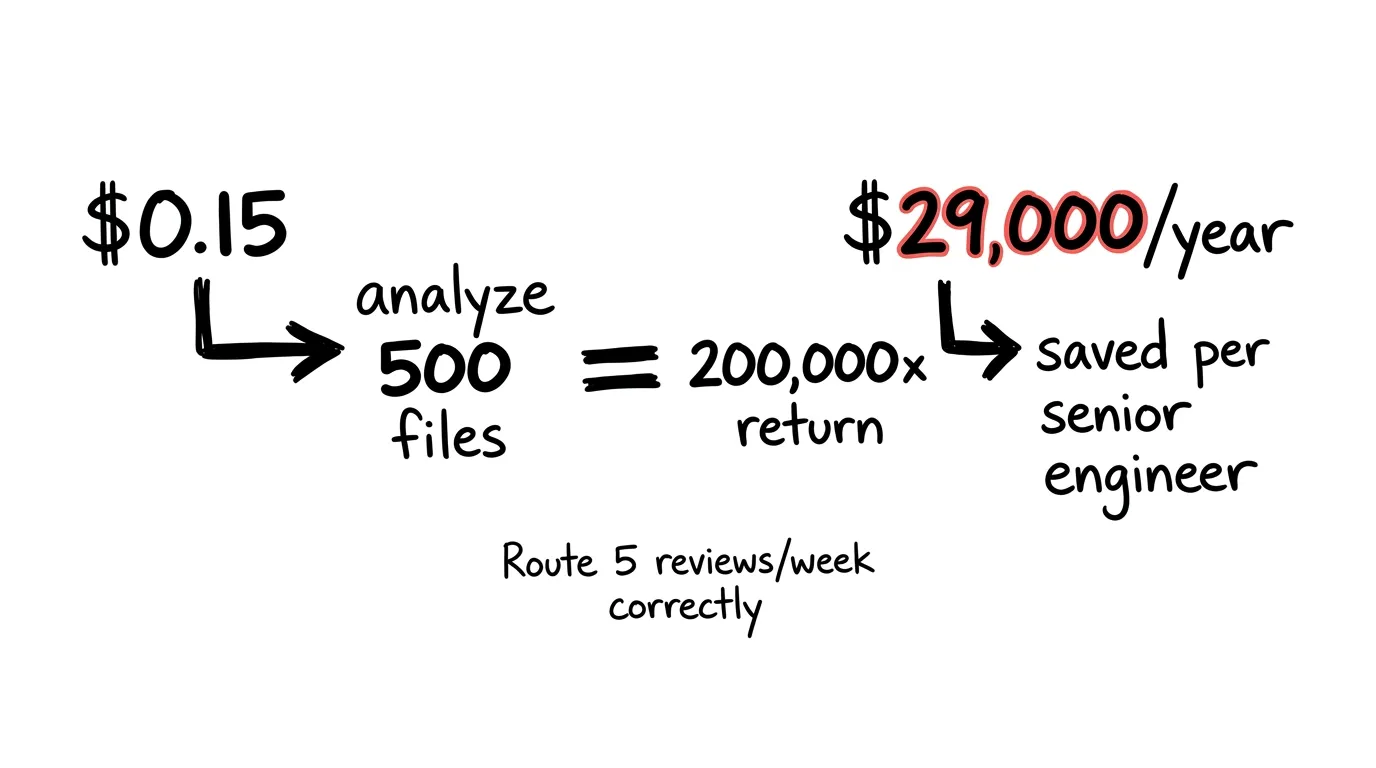
$0.15 to analyze a repo. $0.01 per PR after that.
Compare: a senior engineer spending 45 minutes reviewing a CSS change because it was in the same queue as a token validation fix. At $150/hour loaded cost, that’s $112 wasted per misrouted review.
Route five reviews correctly per week. That’s $29,000 per year per senior engineer in recovered capacity.
Fifteen cents versus twenty-nine thousand dollars. That’s not a 10x gain, it’s a 200,000x gain.
Works with any model, anywhere
HighStakes uses the OpenAI-compatible chat API. No vendor lock-in. I tested it three ways, same binary, zero code changes:
Cloud API (OpenRouter): $0.15 per repo, access to every model. The default.
export OPENROUTER_API_KEY="sk-or-..."
highstakes analyzeModel as a Service (vLLM on OpenShift AI): I pointed HighStakes at Nemotron Nano 3 running on an 8xH200 GPU cluster. No external API, code stays on your infrastructure, zero cost per query.
export HIGHSTAKES_API_KEY="$(oc whoami -t)"
export HIGHSTAKES_API_URL="https://nemotron-nano-3.apps.your-cluster.dev/v1/chat/completions"
highstakes analyze --model nvidia/nemotron-3-nanoIt scored scorer.go (core calculation engine) at 53 MEDIUM with “Scores code changes for tiering,” while test files scored 22 LOW. Same differentiation as the cloud API, from a model running on your own cluster.
Local Ollama: I also tested with Qwen 1.7B on my laptop. No internet, no GPU cluster, no cost at all.
export HIGHSTAKES_API_KEY="ollama"
export HIGHSTAKES_API_URL="http://localhost:11434/v1/chat/completions"
highstakes analyze --model qwen3:1.7bBoth models agreed on the ranking: scorer.go and gitanalyzer.go are the most critical files. Test files and config are safe. The 1.7B model had more JSON parse failures (46% vs 38%), but when it succeeded, its scores were in the same range as Nemotron.
The point: you choose where your code goes. Cloud API for convenience, your own infrastructure for privacy, local laptop for zero dependency. Same tool, same output format.
Who this is for
You’re an engineering lead or senior IC. Your team adopted AI coding tools. Your review queue tripled. You’re either spending all your time reviewing code that doesn’t need you, or you’re letting things merge that shouldn’t.
HighStakes tells you which is which.