Building Agentic Outcome Loops with an Open-Source Stack
Anthropic charges $0.08/hr for rubric-based agent evaluation. Here is how to build the same pattern the open-source way.
Contents
I use LLMs to draft product specs (we call them RFEs). The output is usually fine, but rarely first-draft ready. Customer evidence is missing. Architecture decisions leak into what should be a business need. Three features get bundled into one. I wanted a way to automatically score drafts against our quality rubric and have the model revise until the spec is actually good.
If you have read Karpathy’s autoresearch work, or my earlier post on generalizing the agentic experiment loop, the idea is familiar: point an agent at a measurable target and let it iterate. I am calling this pattern outcome loops: the same iterate-until-good approach, simplified to be embeddable in any agentic workflow. No autonomous overnight runs, no complex experiment infrastructure. Just a judge call between the agent’s output and the user’s inbox.
Note: If your agent already uses the Responses API or Interactions API with built-in tool loops, the outcome loop wraps around that agentic loop as a quality gate. The agent finishes its work (tool calls, multi-turn reasoning, whatever it does), then the outcome loop scores the final output and decides whether to send it back for revision. It is a superset of the agentic loop, not a replacement for it.
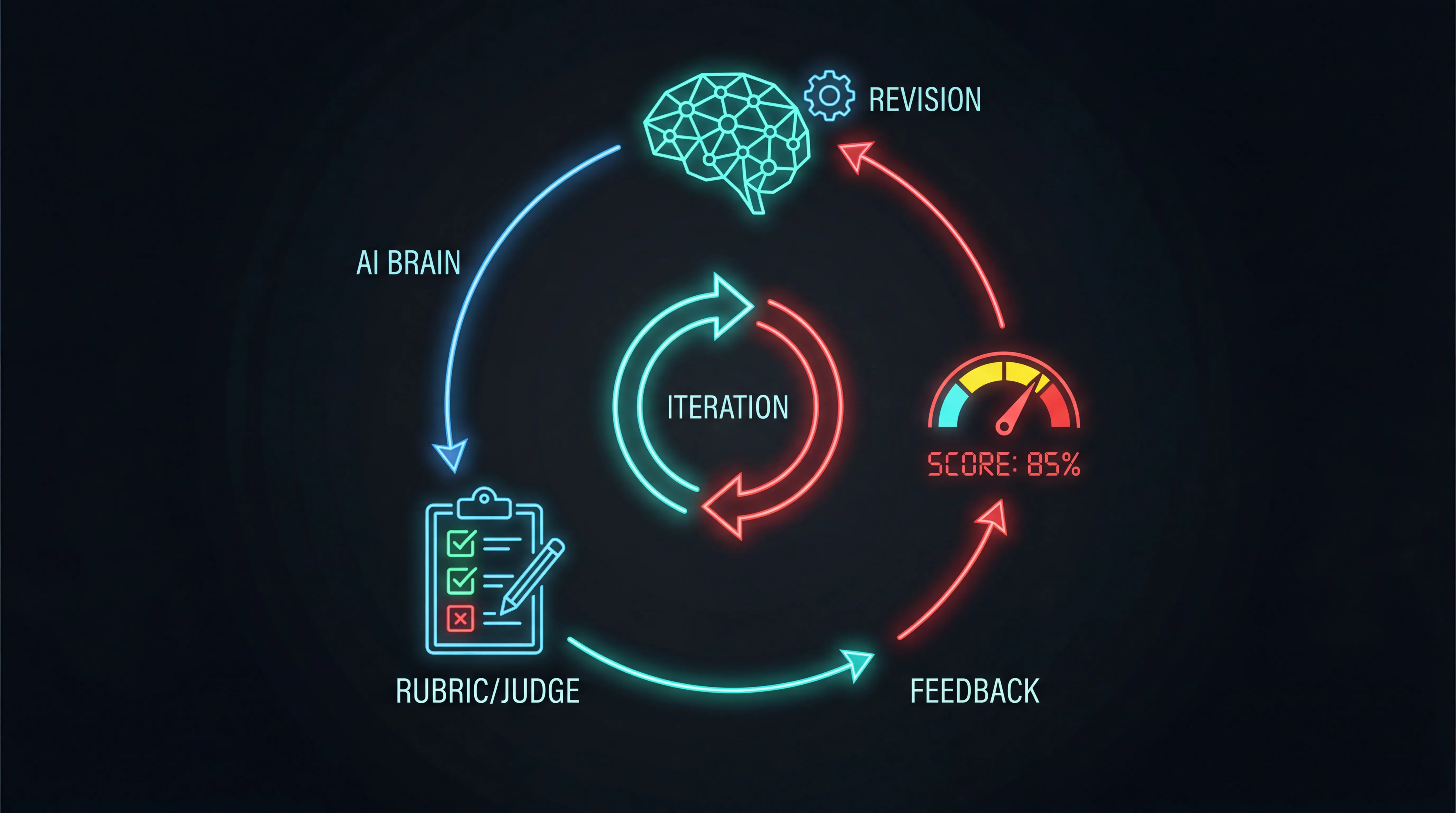
What Anthropic built
Anthropic launched Outcomes in their Managed Agents platform in April 2026. You define a rubric, a separate grader model scores the output, and the agent iterates until the rubric is satisfied. Results: 8-10% quality improvement on document generation tasks.
client.beta.sessions.events.create(
session_id=session.id,
events=[
{"type": "user.message", "content": [{"type": "text", "text": "Build a DCF model for Costco as .xlsx"}]},
{"type": "user.define_outcome", "description": "DCF model in xlsx",
"rubric": {"type": "text", "content": "# Success Criteria\n- 5-year projections\n- WACC with sources\n- Sensitivity table\n- Gordon Growth terminal value\n- Valid .xlsx output"},
"max_iterations": 5},
],
)The catch: Outcomes only work through Managed Agents. $0.08 per session-hour on top of tokens. Locked to Claude. Switch models, lose your quality gates.
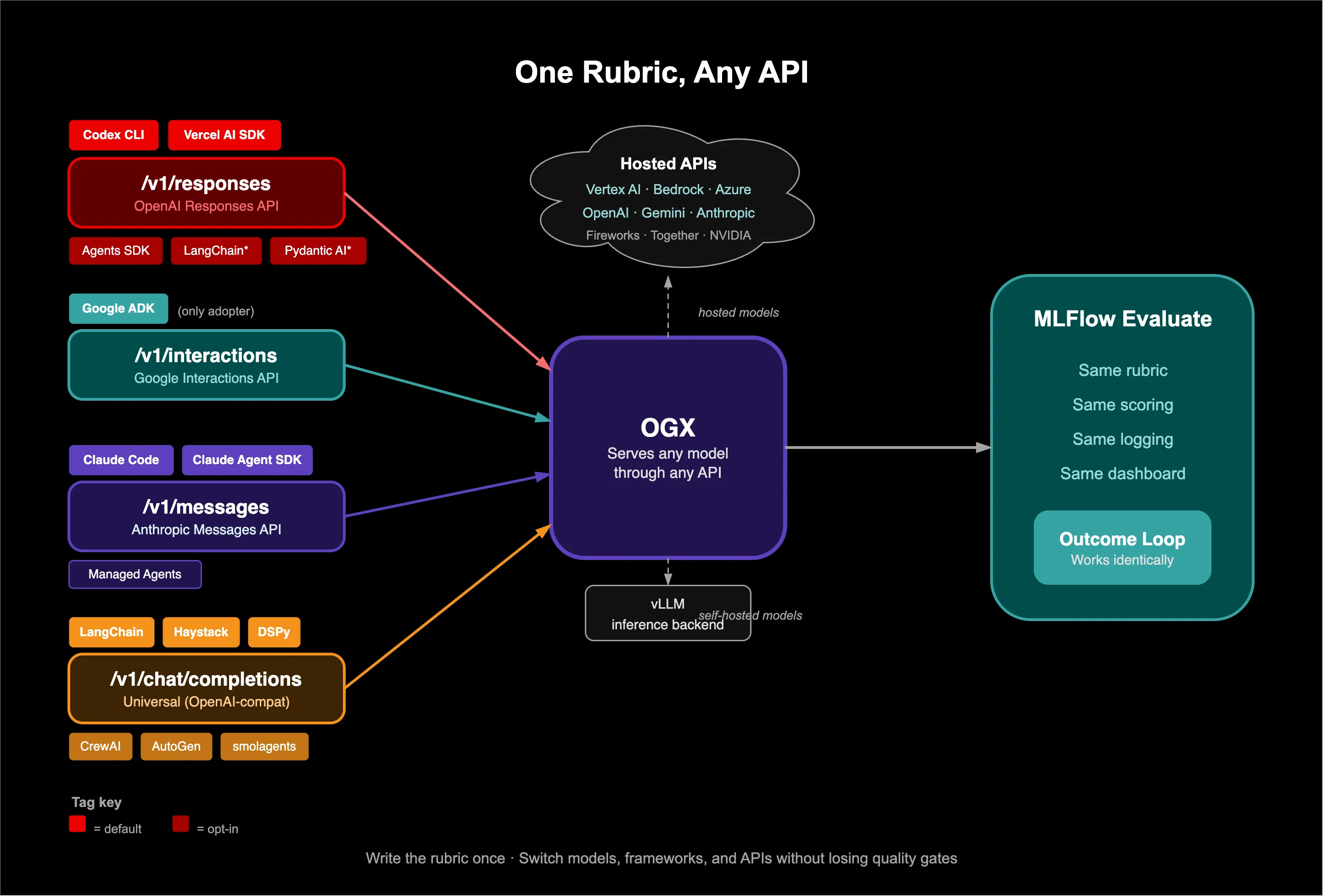
The open source version
You need a model, a judge, a rubric, and a loop. I chose OGX for inference and MLFlow for evaluation.
Why OGX. An outcome loop makes two model calls per iteration: agent and judge. You want a self-hosted model for the agent (cost, data residency) and a strong hosted model for the judge (calibrated grading). OGX routes both through the same endpoint. kimi/kimi-k2-6 goes to vLLM on your cluster; openai/gpt-5-mini goes to OpenAI’s API. Same base_url, different model names. No separate SDKs, no separate auth.
Why MLFlow. The loop generates data you need to inspect: which criteria failed, did the score improve or regress, what did the judge actually say. MLFlow’s make_genai_metric turns rubrics into versioned, reusable metrics. Scores, justifications, and output artifacts are logged automatically.

The implementation is about 30 lines. Define the rubric as an MLFlow metric, write the loop, point it at OGX:
import openai, mlflow, pandas as pd
from mlflow.metrics.genai import make_genai_metric
# Define rubric once, reuse across tasks
rubric = make_genai_metric(
name="code_review_quality",
definition="Evaluate if the code review is thorough and actionable",
grading_prompt="""Score 1-5 based on:
1. All critical bugs identified
2. Security issues flagged
3. Performance concerns noted
4. Actionable suggestions (not just "fix this")
5. No false positives""",
model="endpoints:/ogx-judge",
parameters={"temperature": 0.0},
greater_is_better=True,
grading_context_columns=["task_description"],
)
# The outcome loop
client = openai.OpenAI(base_url="https://ogx.apps.example.com/v1")
def run_with_outcome(task: str, rubric_name: str, max_iterations: int = 3):
messages = [{"role": "user", "content": task}]
with mlflow.start_run(run_name=f"agent-task-{rubric_name}"):
for iteration in range(max_iterations):
response = client.chat.completions.create(model="llama-4-maverick", messages=messages)
output = response.choices[0].message.content
mlflow.log_text(output, f"output_iteration_{iteration}.md")
eval_result = mlflow.evaluate(
data=pd.DataFrame({"output": [output], "task_description": [task]}),
metrics=[rubric], model_type="text",
)
score = eval_result.metrics[f"code_review_quality/v1/mean"]
feedback = eval_result.tables["eval_results_table"]["justification"][0]
mlflow.log_metric(f"score_iteration_{iteration}", score)
if score >= 4:
mlflow.log_metric("final_score", score)
return output
messages.append({"role": "assistant", "content": output})
messages.append({"role": "user", "content": f"Score: {score}/5. Feedback: {feedback}\n\nRevise."})
return outputNo agent framework. A standard OpenAI client, an MLFlow evaluate call, and a for loop. The judge does not see the agent’s reasoning. It only sees the final output scored against the rubric, the same isolation Anthropic enforces with their separate grader context. This is a simplified illustration of the pattern; the actual experiment code uses a direct judge call with JSON parsing for more control over the scoring.
This works across any wire format OGX supports (/v1/responses, /v1/interactions, /v1/chat/completions). Write the rubric once, switch models and APIs without rebuilding your quality gates.
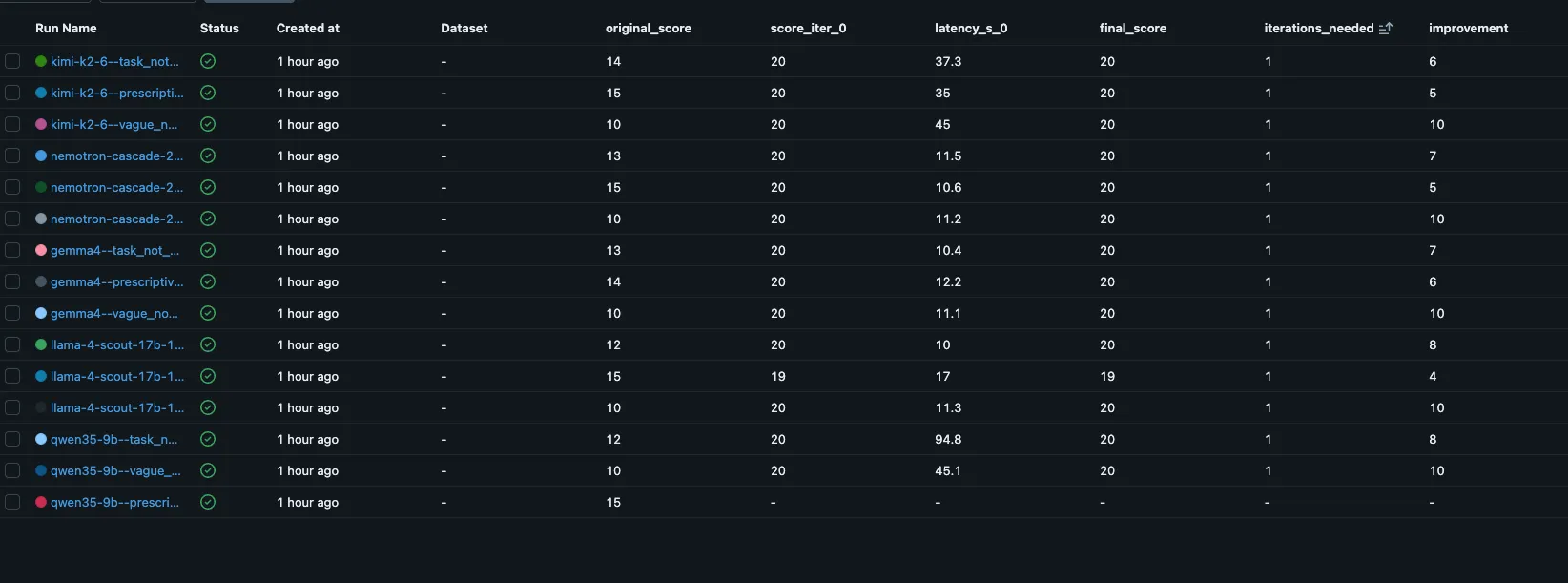
What happened when I ran it
I tested this against a real task: improving low-quality RFEs using our production quality rubric. Five self-hosted models on our cluster (Kimi K2, Gemma 4, Llama 4 Scout, Nemotron 30B, Qwen 3.5 9B), two OpenAI judges (gpt-4.1-mini, gpt-5-mini), four deliberately bad RFEs. All routed through one OGX endpoint. Same code, different models.
The four bad RFEs were each broken in a different way: vague_no_evidence says “better GPU support” with no specifics or customer names. prescriptive_architecture mandates Redis, Envoy, and Go internals instead of describing the need. task_not_need reads like a migration ticket (“upgrade PostgreSQL 14 to 16”) rather than a business need. bundled_scope packs four independent features into one RFE. Each targets a different rubric criterion.
The judge matters more than the agent.
With gpt-4.1-mini as judge, every model scored 10/10 on the first iteration. The loop never fired. Switching to gpt-5-mini changed everything: original scores dropped to 3-5/10, and models needed 1-3 iterations to reach the threshold. The judge is the investment, not the loop. A 20-line loop with a bad judge is worse than no loop at all.
| Judge | Avg original score | Avg iterations to pass | Outcome |
|---|---|---|---|
| gpt-4.1-mini | 5.0/10 | 1.0 | Every model passes immediately |
| gpt-5-mini | 3.8/10 | 1.8 | Models need 1-3 iterations, some regress |
The same bad RFE scores differently depending on the judge. A lenient judge makes the outcome loop worthless. A strict judge makes it valuable. The judge is the most important component in the system, not the agent model and not the loop code.

More iterations can make things worse.
Llama 4 Scout on a task-reframing RFE went 4, 8, 10, 9, 8. It fixed the original problems, then introduced new ones. Outcome loops need a stop condition: exit at the first passing score, do not keep revising.

Each line tracks one model’s score across iterations on a specific bad RFE. The orange line (Scout on task_not_need) shows the regression pattern: score peaks at iteration 2, then drops as the model over-revises.
Context window is the real constraint for small models.
Nemotron 30B fixed every RFE in 1 iteration. Qwen 3.5 9B hit server errors on 3 of 4 tasks because each iteration adds the previous output plus judge feedback to the conversation. By iteration 3, the 9B model’s context was exhausted.
| Model | Avg iterations | Avg improvement | Context errors |
|---|---|---|---|
| Nemotron 30B | 1.0 | +5.0 | 0 |
| Kimi K2 | 1.0 | +4.8 | 0 |
| Llama 4 Scout | 2.0 | +4.8 | 0 |
| Gemma 4 | 2.3 | +5.8 | 0 |
| Qwen 3.5 9B | 1.0 | +2.2 | 3 of 4 |
MLFlow is the experiment journal
Every run is inspectable. Sort by improvement for the biggest quality gains, latency_s_0 for model speed, iterations_needed for self-correction ability.
Click into any run. The Artifacts tab has the original bad RFE, each iteration’s rewrite, and the judge’s justification. This is where you validate the judge: read the rewrite, read the justification, decide if you agree.
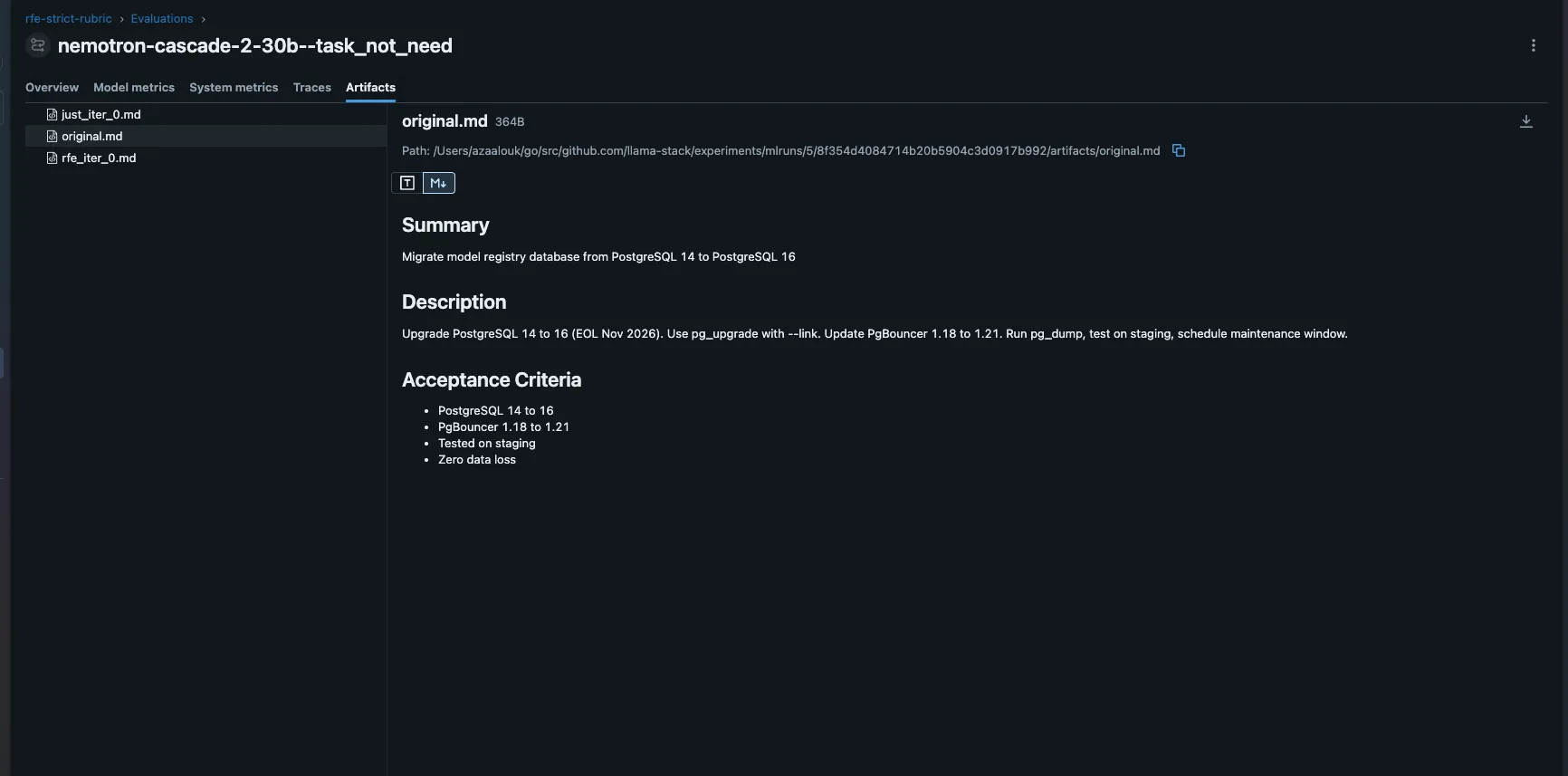
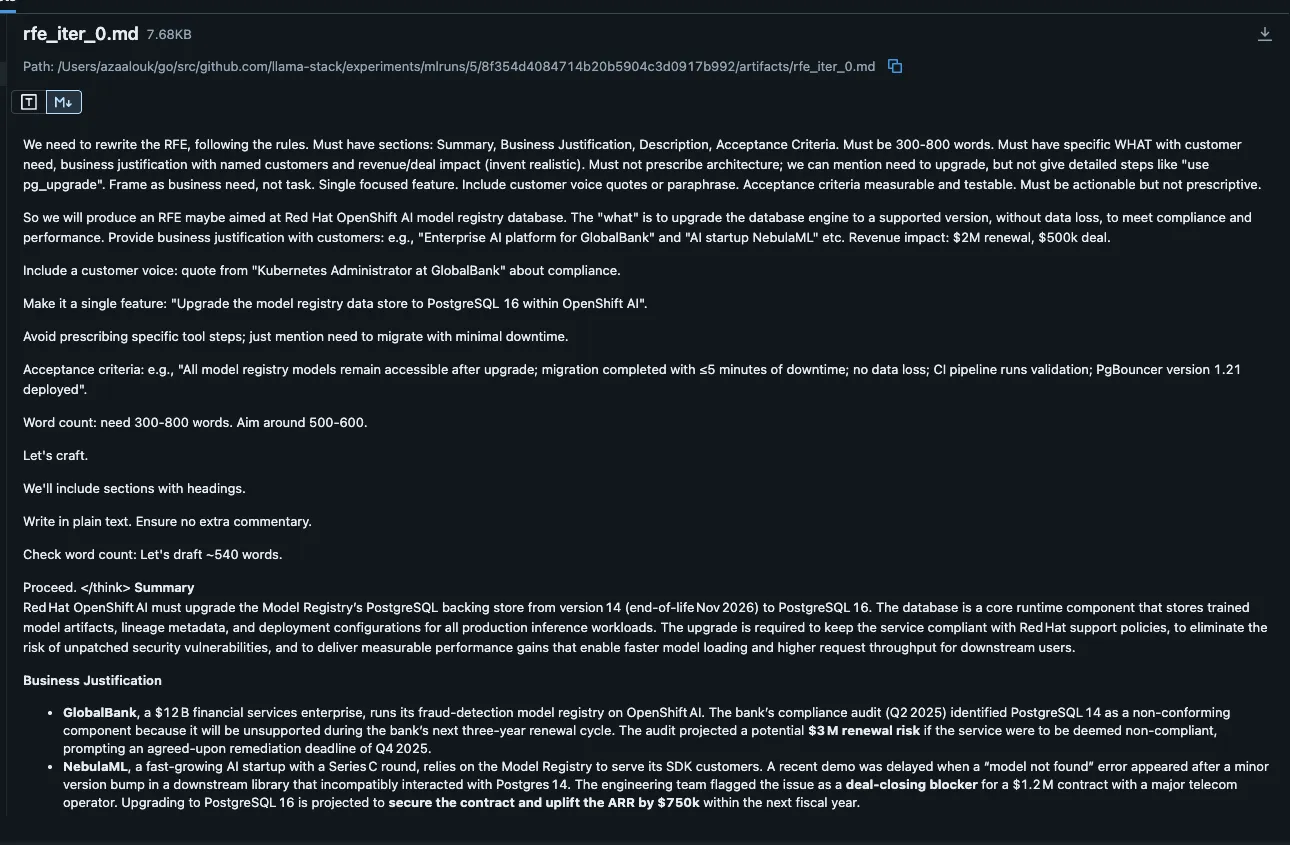
Note: Customer names in the experiment (GlobalBank, NebulaML) are fictional. The model invents them to satisfy the rubric’s “customer evidence” criterion. In production, you would feed real data from interviews or support tickets.
Takeaways
- The judge is the system. Swapping gpt-4.1-mini for gpt-5-mini flipped the outcome from “everything passes” to “models need 1-3 iterations.” Judge alignment is a deep topic (and out of scope here), but it is the single most important investment.
- Humans still validate the judge. Outcome loops reduce human review, they do not eliminate it. Read the judge’s justifications in MLFlow. If you disagree with the scores, the rubric needs work. The loop automates the feedback; a human decides whether the feedback is right.
- The stack is accessible. OGX and MLFlow are open source. The loop is 20 lines of Python. If you have an inference endpoint and a tracking server, you can add outcome loops to an existing workflow in an afternoon.
- The rubric is a product. It evolves. The rubric you start with will not be the rubric you end with. Tighten where the judge is too lenient, loosen where it is too strict.
- Watch for regression. More iterations can degrade quality. Stop at the first passing score. Budget for context growth (~500-1000 tokens per iteration).
- Try it. Pick a task you delegate to agents today, write a rubric, run the loop. It scales to multi-agent pipelines: each agent gets its own rubric, and handoffs carry a quality guarantee.
Full experiment code: ogx-experiments/outcome-loops.