Beyond LLMs: Anatomy of Agentic Systems
From compound AI systems to the agentic loop, MCP, APIs, frameworks, and the rise of the Claws — a technical map of what it takes to build with AI agents in 2026.
Contents
This is Part 2 of a three-part series on building real products with AI. Part 1 covered the product thinking framework. This part goes into the technical layers. Part 3 connects it all back to defensibility and the value lifecycle.
In Part 1, I argued that models alone aren’t products. So what turns a model into something useful? This is where it gets technical.
Nobody Can Agree on What an Agent Is
Let’s start here because it matters. There’s a quote from a 1994 paper by Michael Wooldridge and Nicholas Jennings — Intelligent Agents: Theory and Practice — that I keep coming back to:
“Although the term is widely used by many people working in closely related areas, it defies attempts to produce a single universally accepted definition.”
— Michael Wooldridge & Nicholas Jennings, Intelligent Agents: Theory and Practice (1994)

That was 1994. It’s still true in 2026. OpenAI has a definition, Anthropic has one, Google has one, IBM has one. They all describe some form of autonomous system trying to reach an outcome. But the definitions differ.

What I find most useful is Anthropic’s distinction: an agentic system is a distributed system composed of parts that derive autonomy and lead to outcomes. It separates the system from the agent, which matters when you’re actually building these things.
Compound AI Systems
In February 2024, Matei Zaharia and colleagues at the Berkeley AI Research group published a piece on compound AI systems. The core idea: what you interact with when you use ChatGPT isn’t just a model. It’s a system.
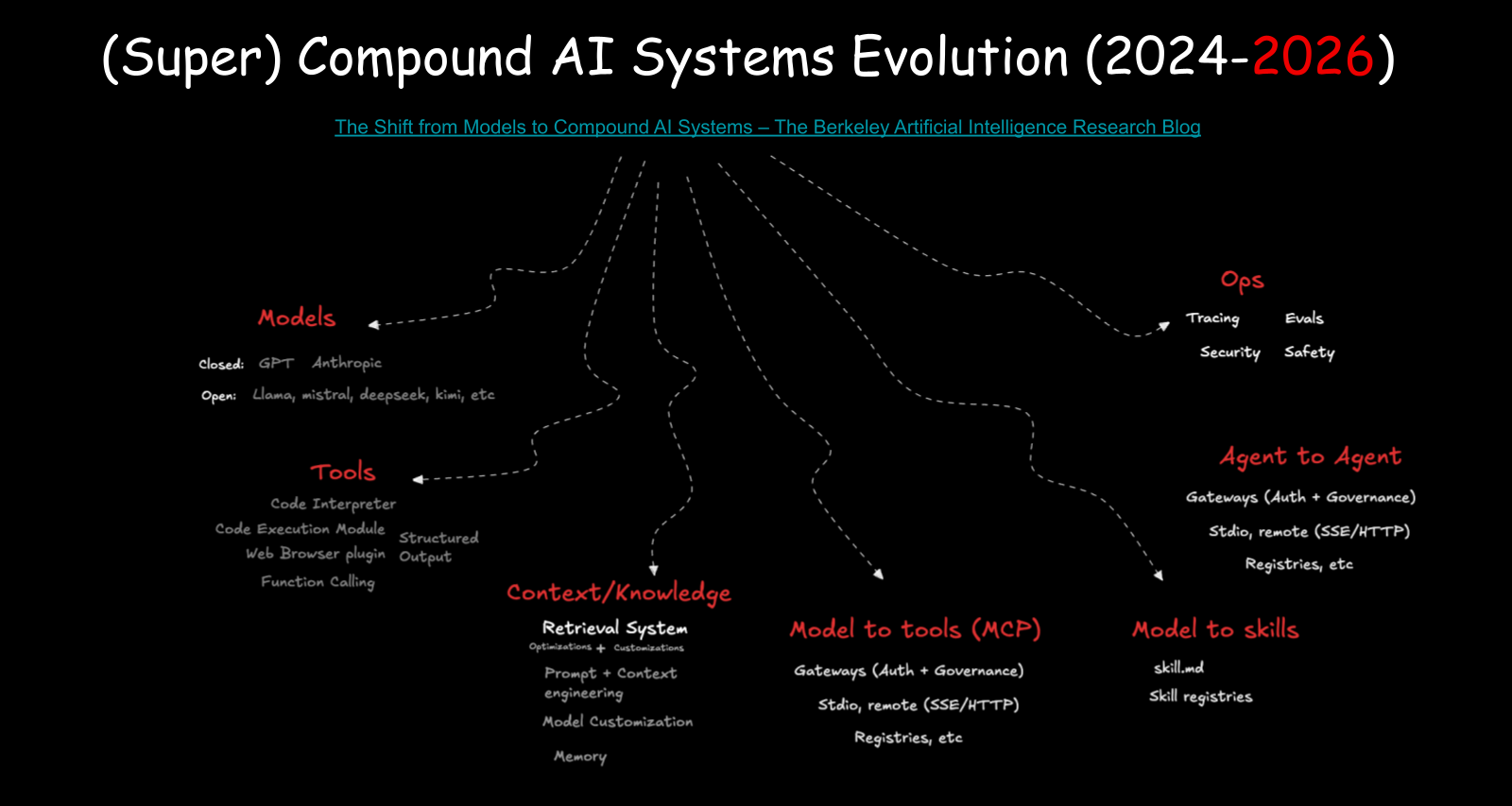
That system has a lot of parts, and I’ll walk through the ones that matter most.
Models
The decision engine. We now have strong open source options (Llama, Mistral, DeepSeek) getting close to parity with closed models (GPT, Claude). You can run a 32GB model on your laptop and have meaningful intelligence locally.
Tools and structured output
Models don’t call APIs. They output text that gets formatted into decisions. They were specifically trained to produce JSON, select tool schemas, and return structured parameters. The model is a selection brain: you give it options, it picks which function to call, and your application executes it.
Context and retrieval
Semantic embeddings and vector search changed how we find relevant information. Two words can be completely different in keyword space but nearly identical in semantic meaning. RAG (retrieval-augmented generation) brings external knowledge into the model’s context window (I covered why retrieval keeps winning in RAG Reigns Supreme).
Context engineering
How you fill the model’s context window matters a lot. The model is lossy for content in the middle of the window (the “needle in a haystack” problem). What goes at the beginning and end gets more attention. In June 2025, Karpathy wrote about “context engineering” as a discipline — the idea that what goes into that input window affects quality as much as the model itself.
Model customization
Parameter-efficient fine-tuning (LoRA, QLoRA) lets you specialize a model without training from scratch. You trim specific layers, add new ones, and get a model specialized in your domain. Model X plus layer Y gives you something new.
MCP
Before MCP (Model Context Protocol), every application had to write its own tool schemas. Anthropic announced MCP in November 2024 and it standardized how tools are discovered and described so that any application can query a server, get a set of well-defined schemas, and pass them to the model. Within months, over 1,000 community MCP servers appeared. Anthropic now maintains an official MCP server registry. There’s no equivalent official registry for agents yet, though I built one as a side project. And because MCP went big, we now have to secure it with gateways that understand the protocol (see also the Claw Gateway Network Atlas illustration). I wrote more about MCP’s economics in Standardizing AI Value.
 Interactive
Interactive Skills
Prompts accessible by semantic search. You learn something, encode it as a skill, and next time the system queries for a relevant prompt, it finds the best match. It works like how we learn: write it down, go back to it, eventually internalize it. Continuous fine-tuning is the internalization step.
A2A
In April 2025, Google introduced the Agent-to-Agent (A2A) protocol for agents to communicate with each other. It supports long-lived streaming, authentication, mTLS, and identity. Different from MCP, which is about tool discovery.
Operations
Tracing, evaluation, security, safety. Models make many decisions per day. You need to know which tools they chose and whether those choices were right. Evaluation is often just domain experts looking at output. A lawyer reading contract summaries. A German speaker checking German translations. Then you need guardrails for when the model does something unexpected, and red-teaming to stress-test it before deployment.
The Agentic Loop
At the center of every agent system is a loop.
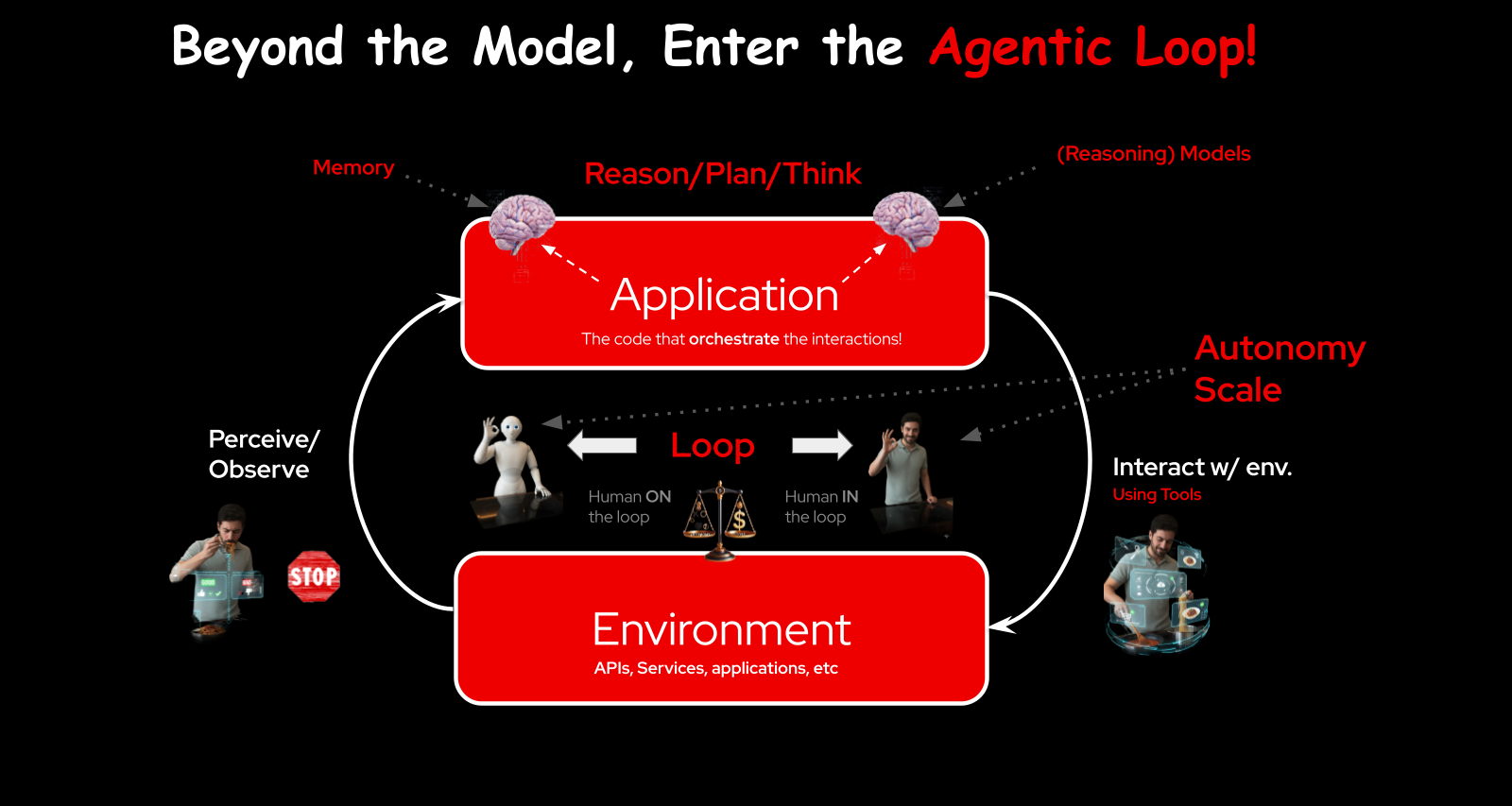
The model receives a query. It reasons about what to do, plans steps, and decides which tools to use. The application calls the tool, interacts with the environment (an API, a service, another application), then perceives the result — was it correct? — and loops back.
Each iteration is a turn. You can stop at each turn for human review (human in the loop), or let it run autonomously (human on the loop). The level of autonomy you grant depends on trust, and trust depends on everything I just described: evaluation, guardrails, tracing, safety.
Delegation works the same way in human organizations. You delegate important tasks to people you trust. Before we delegate important decisions to models, we need the same level of confidence. That confidence comes from the compound system around the model, not from the model itself.
APIs: The Foundation Layer
When GPT first launched, the only interface was a chat window. Then came the APIs, and that opened the floodgates.
The Chat Completions API, released in March 2023, was OpenAI’s first developer API. Simple, clean, easy to wrap application code around. Every framework built on this.
Then in March 2025, OpenAI released the Responses API and moved complexity server-side. Instead of every framework implementing tool calling, handoffs, and context management differently, the Responses API absorbed these into a single endpoint. MCP connections, reasoning loops, human-in-the-loop configuration, vector stores, file search. All in one API.
Anthropic released the Messages API with its own approach to identity and error handling. And at the end of 2025, Google shipped the Interactions API. Their reasoning: if you win the API layer, every framework uses you, every user comes to you.
Three major APIs now govern how we interface with models. It’s a real competition.
To Framework or Not to Framework
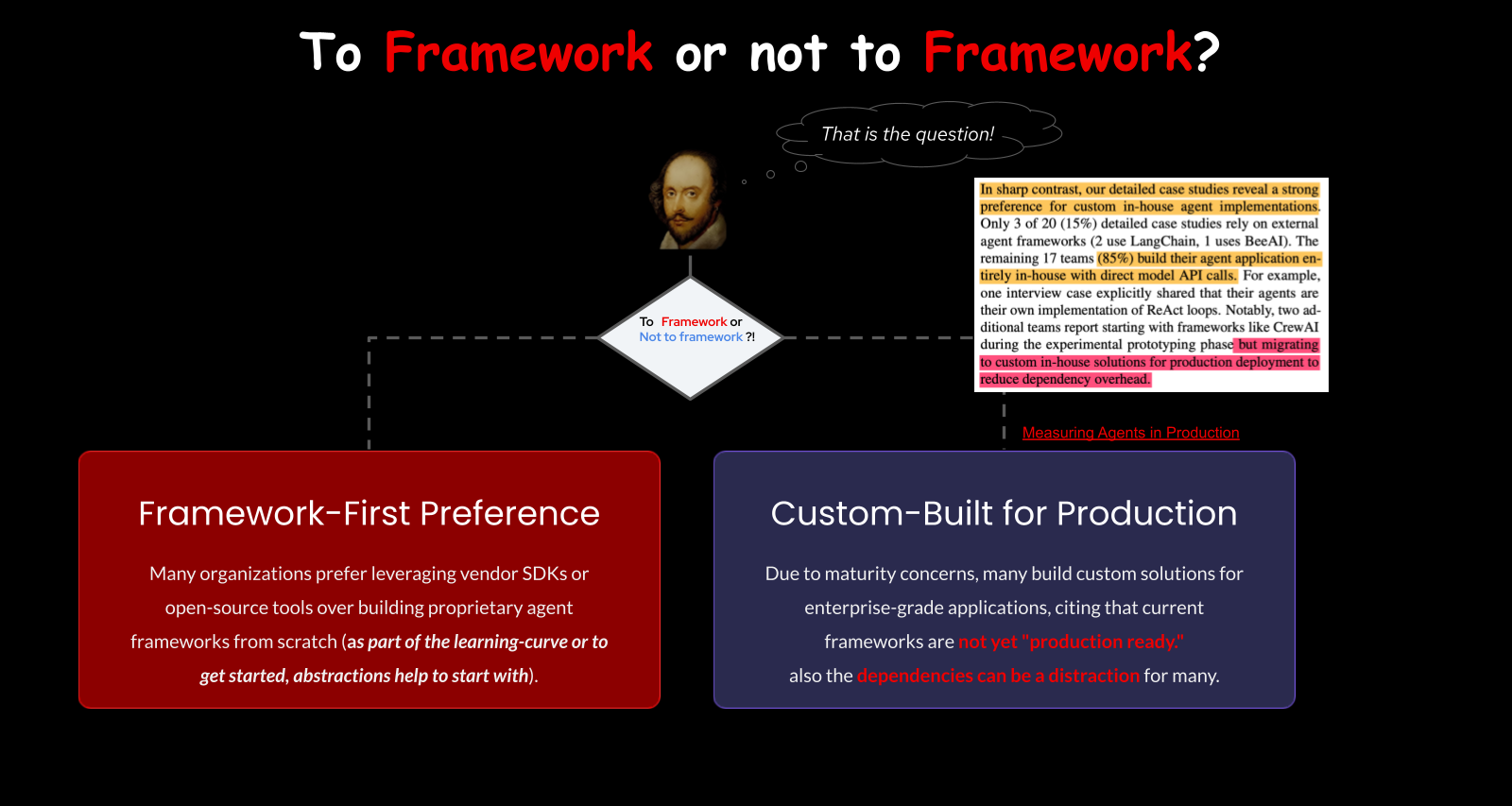
A framework wraps the API and adds opinions. LangChain gives you chains and graphs. CrewAI defines agents as members of a crew. Haystack is strong at RAG pipelines. Google ADK integrates natively with A2A. OpenAI’s Agents SDK has handoffs and guardrails built in. The list goes on — there are dozens.
Here’s the surprising data point: the “State of AI Agents” report by Patronus AI and Berkeley, published in late 2025, found that 85% of people building agents in production don’t use frameworks. They hit the API directly or build thin wrappers. Frameworks are useful for getting started and for learning, but many production systems outgrow them.
The argument mirrors the cloud-native debate. Some people want managed services and abstractions. Others want to control their own networking and hardware. It’s a matter of taste and use case. Frameworks put opinions on how the pieces fit together, and sometimes that opinion doesn’t match your requirements.
The Age of the Claws
Then came the Claws.

Claude Code — Anthropic’s open source CLI released in early 2025 — and tools like OpenClaw showed what happens when you give a model broad autonomy with access to tools (your terminal is an AI runtime now). It triggered an explosion: NanoClaw (just calls the Claude SDK), ZeroClaw (performance-focused), PicoClaw (Rust, Raspberry Pi), IronClaw. Each finds an angle.
What these tools really demonstrated is that you can build the agentic loop fast if you understand networking, models, and tools. It’s wrapper code on top of an agentic loop. Building the loop is the easy part. Making it secure, stable, and deployable is where everyone gets stuck.
That’s where the industry is stuck right now. Everyone wants that level of autonomy. Not everyone has solved how to make it safe for production. Sandboxing, credential management, session isolation, audit trails — the boring but critical infrastructure that turns a demo into a product.
There’s another reason these tools converged on similar stacks: TypeScript became the language of choice not just because it’s popular, but because it’s the “English of programming languages” for AI. Models have been trained on more TypeScript than almost anything else. It’s also part of the loop — the model can modify its own codebase, which is harder with compiled languages.
The harness: what holds it all together
We have covered a lot of components: models, tools, context, MCP, APIs, frameworks, the Claws. But components alone are not a system. Something has to orchestrate them at runtime, deciding what context enters the window, which tools are available, when to compact history, how to enforce safety, and when to stop. That something is the harness.
The formula is simple: Agent = Model + Harness. A raw model is a function: text in, text out. The harness is what makes it an agent: state, tool execution, feedback loops, enforceable constraints.
We got here in three steps. In 2022-2024, the focus was prompt engineering, crafting the right instructions. In 2025, it shifted to context engineering, managing everything the model sees. In 2026, it became harness engineering, building the full system around the model. Each layer subsumes the previous one.
Mitchell Hashimoto named it in February 2026. His framing was simple: every time an agent makes a mistake, engineer a permanent fix into the environment so it never happens again. An AGENTS.md rule. A custom linter. A script that catches a failure mode before the model sees it. Within weeks, OpenAI and Anthropic published their own takes, and the term stuck.
Phil Schmid offered a useful analogy: the model is the CPU, the context window is the RAM, and the harness is the operating system. The OS does not do the computation, but without it, the CPU is just silicon. The harness curates context, handles the boot sequence, provides standard drivers, and manages permissions. When things go wrong, it is usually the OS, not the CPU.
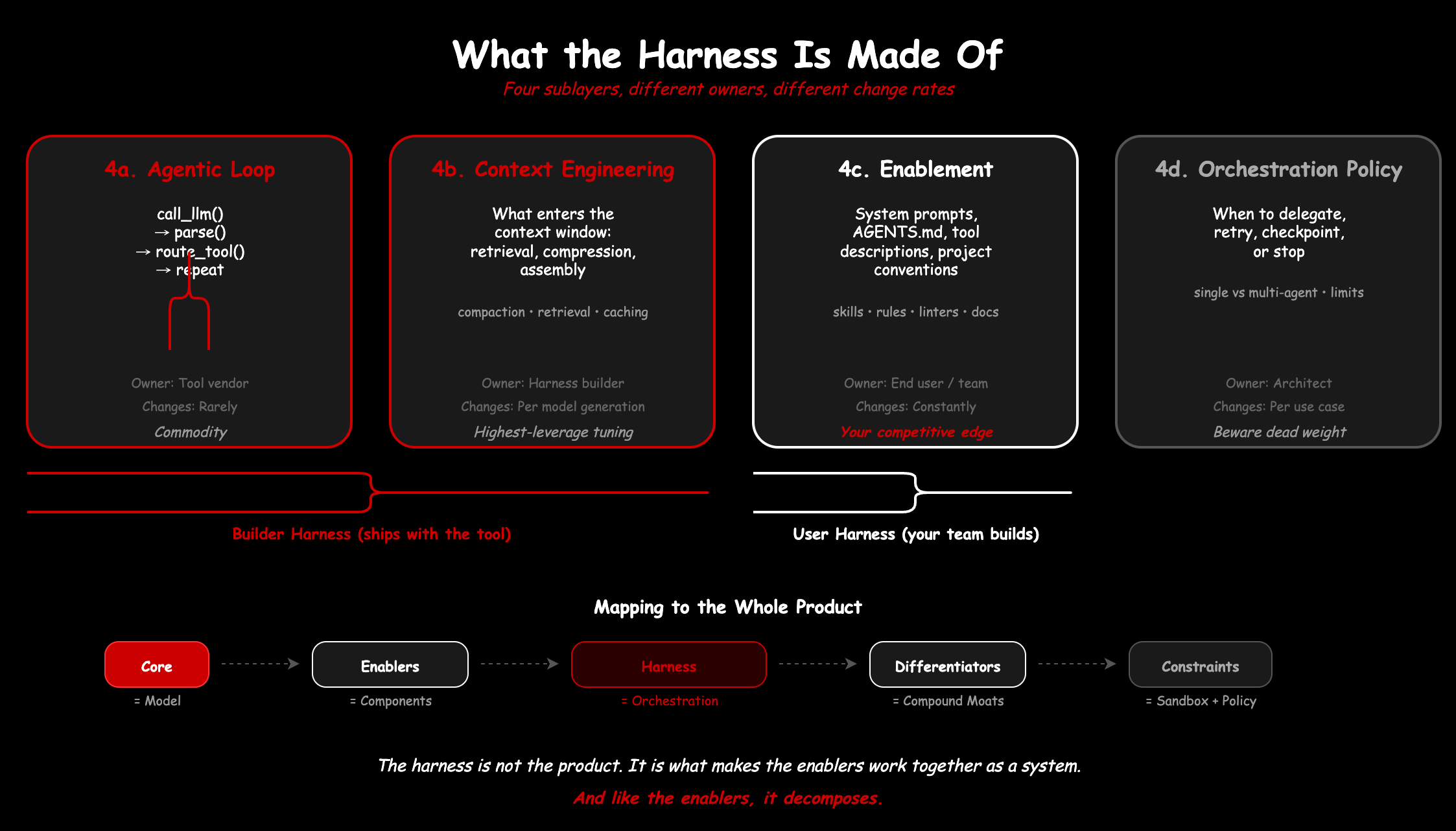
The harness is not the product. The product is the whole composition: model, enablers, differentiators, constraints. But the harness is what makes the enablers work together as a coherent system rather than a bag of parts. And like the enablers themselves, it is not one thing. It decomposes.
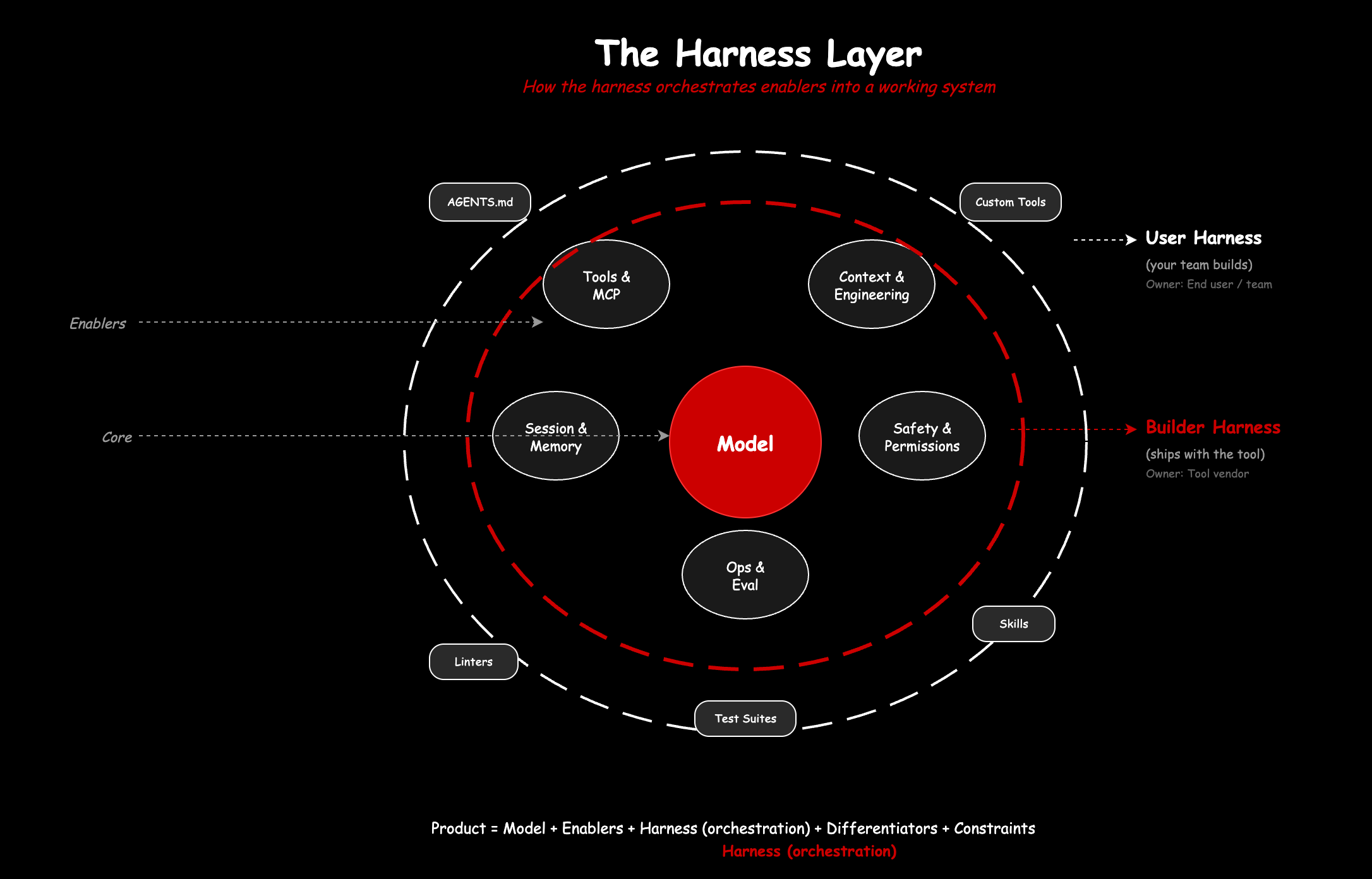
Birgitta Böckeler, writing on Martin Fowler’s site, drew a useful distinction. There is a builder harness, what ships with the tool: the context compaction strategy, the permission model, the session management, the safety layers. Claude Code’s ASK/ALLOW/DENY system, Codex’s sandbox policies, the doom-loop detection in OpenDev. These are architectural decisions baked into the runtime.
Then there is the user harness, what you add on top for your specific project and context. AGENTS.md files. Custom tools. Linters tuned to produce error messages that models can act on. Test suites that serve as feedback sensors. This is enablement in the language of Part 1, the petals that complete the whole product.
The builder harness changes rarely and is owned by the tool vendor. The user harness changes constantly and is owned by your team. Both are composed of the same types of concerns (context, safety, tools, memory), just at different layers of ownership.
The numbers back this up. Stanford’s Meta-Harness paper found that harness design alone can cause up to a 6x difference in model performance on the same benchmark. Same model weights, same inference endpoint, different harness, wildly different results. LangChain proved it practically: changing only the harness moved their coding agent from outside the top 30 to the top 5 on TerminalBench 2.0. In the Hashline experiment, the same model jumped from 6.7% to 68.3% with zero weight changes. The Claws all prove this too. They use the same models. They differ in harness design. That is why they produce different outcomes.
In the whole product framework from Part 1: the model is the core. The compound system components (tools, context, MCP, ops) are the enablers. The harness is the orchestration that turns those enablers into a working system. And the user harness, the project-specific rules and tools you build up over time, is where your team’s competitive edge accumulates.
What comes next
We have covered the technical stack and how it composes into a working system through the harness. All of this forms the features and activities layer of the whole product model from Part 1.
But features alone don’t make a defensible product. In Part 3, we’ll talk about what does: moats, distribution, case studies from NVIDIA, OpenAI, and Anthropic, and how to map the entire AI product evolution onto Moore’s technology lifecycle.