Beyond LLMs: Moats, Distribution, and the Value Lifecycle
What makes one AI product defensible against another? Data, specialization, compound moats, and how the whole AI product stack maps to Moore's technology lifecycle.
Contents
This is Part 3 of a three-part series exploring AI products beyond the model layer. Part 1 covered the product framework. Part 2 went through the technical anatomy of agentic systems. This final part connects everything to defensibility and the value lifecycle.
We covered the product framework. We covered the technical stack. Now the question is: everyone is building with these same tools and APIs and models. What actually makes one AI product defensible against another?
Connecting Systems to Products
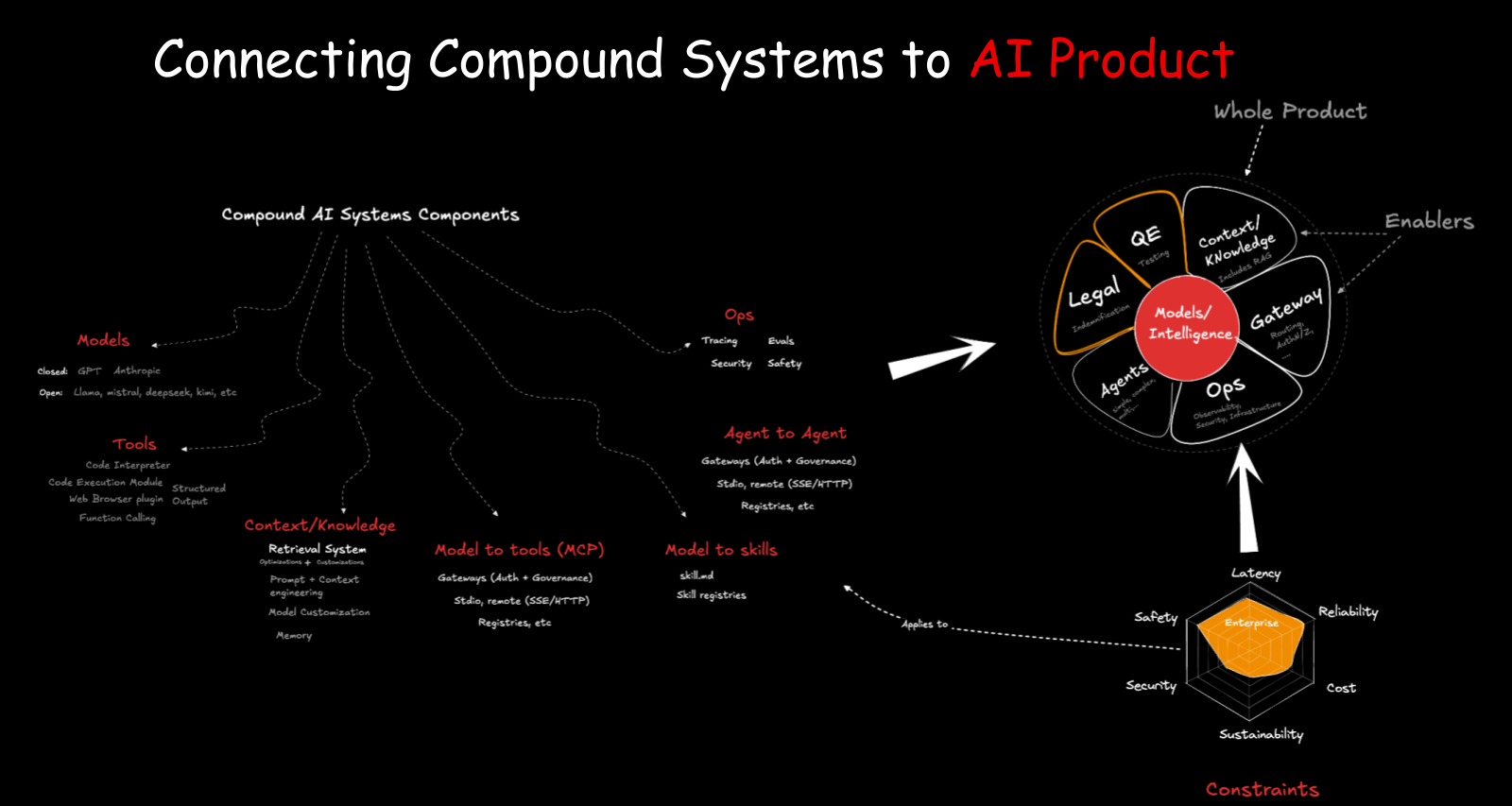
At the center of every AI product sits the model — the brain. Around it, you build the compound system: context, knowledge, gateways, tools, evaluation, operations. These are your features. Then you add activities: testing, legal review, QE, support. Together they form the whole product.
Take the Claws we discussed in Part 2. Each one is essentially the same agentic loop, but with different constraints applied. Care about safety? Use IronClaw. Need low latency? PicoClaw runs in Rust. Need reliability and enterprise support? Different constraints produce different sub-products for different customer segments — exactly like the Slack example from Part 1.
What Is a Moat?
Warren Buffett popularized the “economic moat” concept — the thing around the castle that prevents enemies from getting in. In business, it’s what prevents competitors from replicating what you’ve built. Hamilton Helmer’s 7 Powers framework (2016) lays out the types of competitive advantage that endure: scale economies, network effects, switching costs, counter-positioning, branding, cornered resources, and process power. All of these show up in the AI landscape.
Everyone can build with AI right now. I built a game with my son by just telling the model what to do. According to McKinsey’s 2024 “State of AI” report, 72% of organizations had adopted AI in at least one function, up from 55% in 2023. So the model isn’t a moat. If everyone has access to the same intelligence, what sets you apart? (I explored this tension between open and closed approaches in AI Market Dynamics: Open Vs. Closed, Direct Vs. Indirect.)
There are different types of moats:
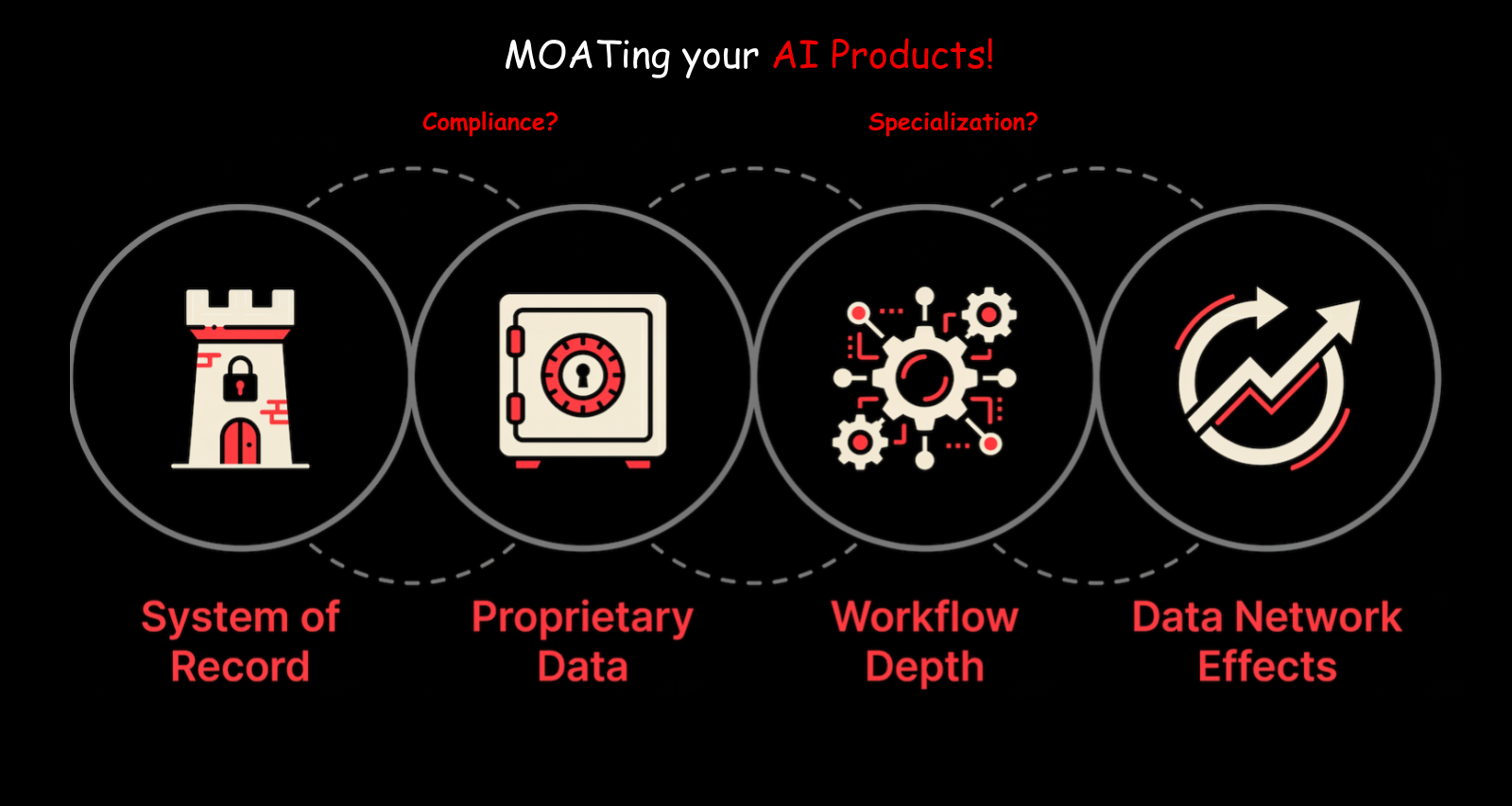
Data — Proprietary data that nobody else has. A healthcare company with patient data approved for AI training. A financial firm with decades of transaction patterns. Your company’s unique data is one of the strongest moats.
Specialization and workflow depth — Domain expertise will become increasingly valuable. Companies that have deep knowledge of how things work — SREs who’ve been troubleshooting Kubernetes for years, legal teams who understand contract law — have valuable data and workflows that combine powerfully with models. A Kubernetes troubleshooting agent built by people who’ve been doing Kubernetes operations for a decade will outperform one built by a team that just learned Kubernetes.
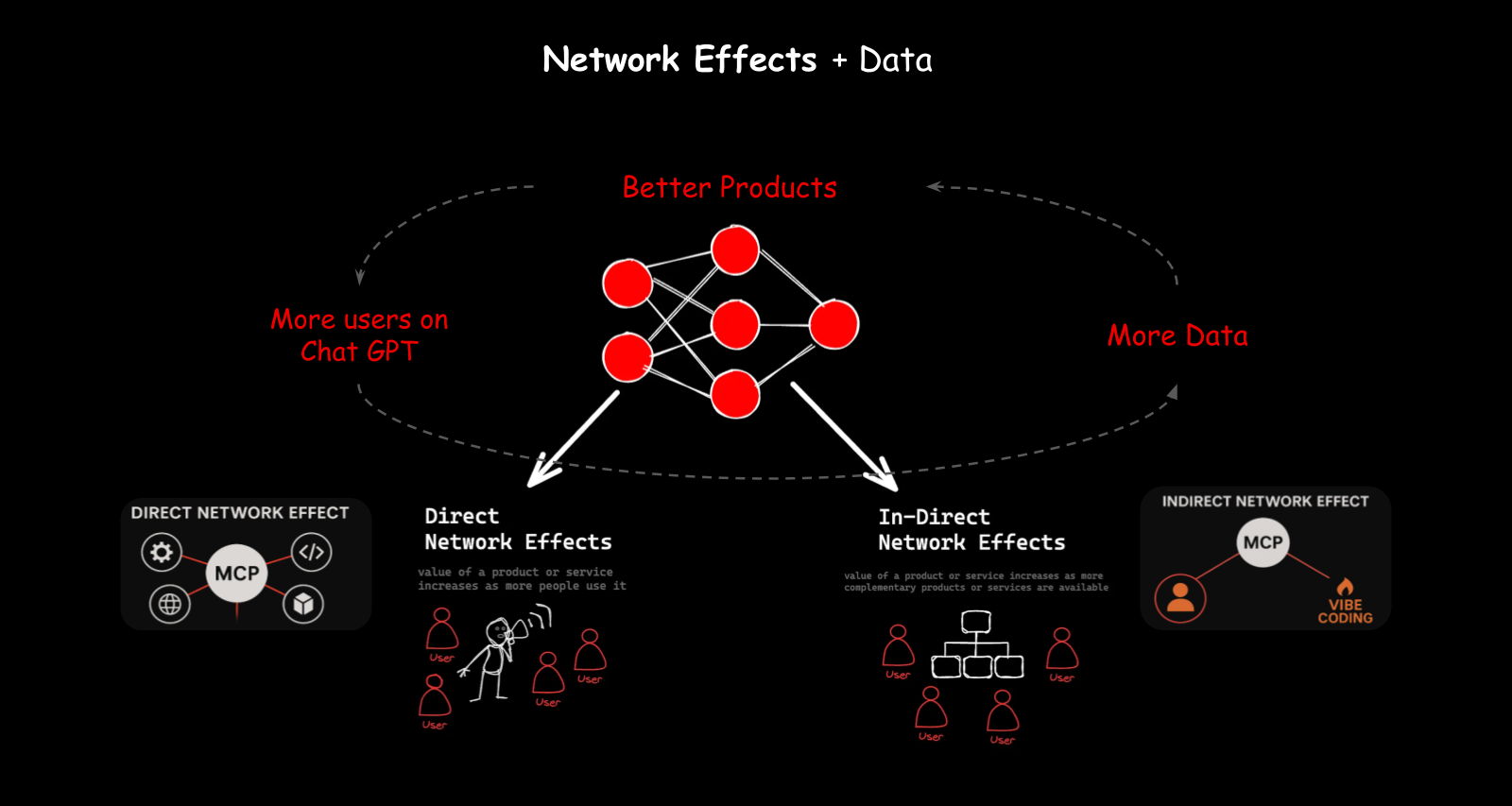
Network effects and distribution — More users means more data. More data means better products. Better products attract more users. This is the flywheel that companies like OpenAI have built with ChatGPT.
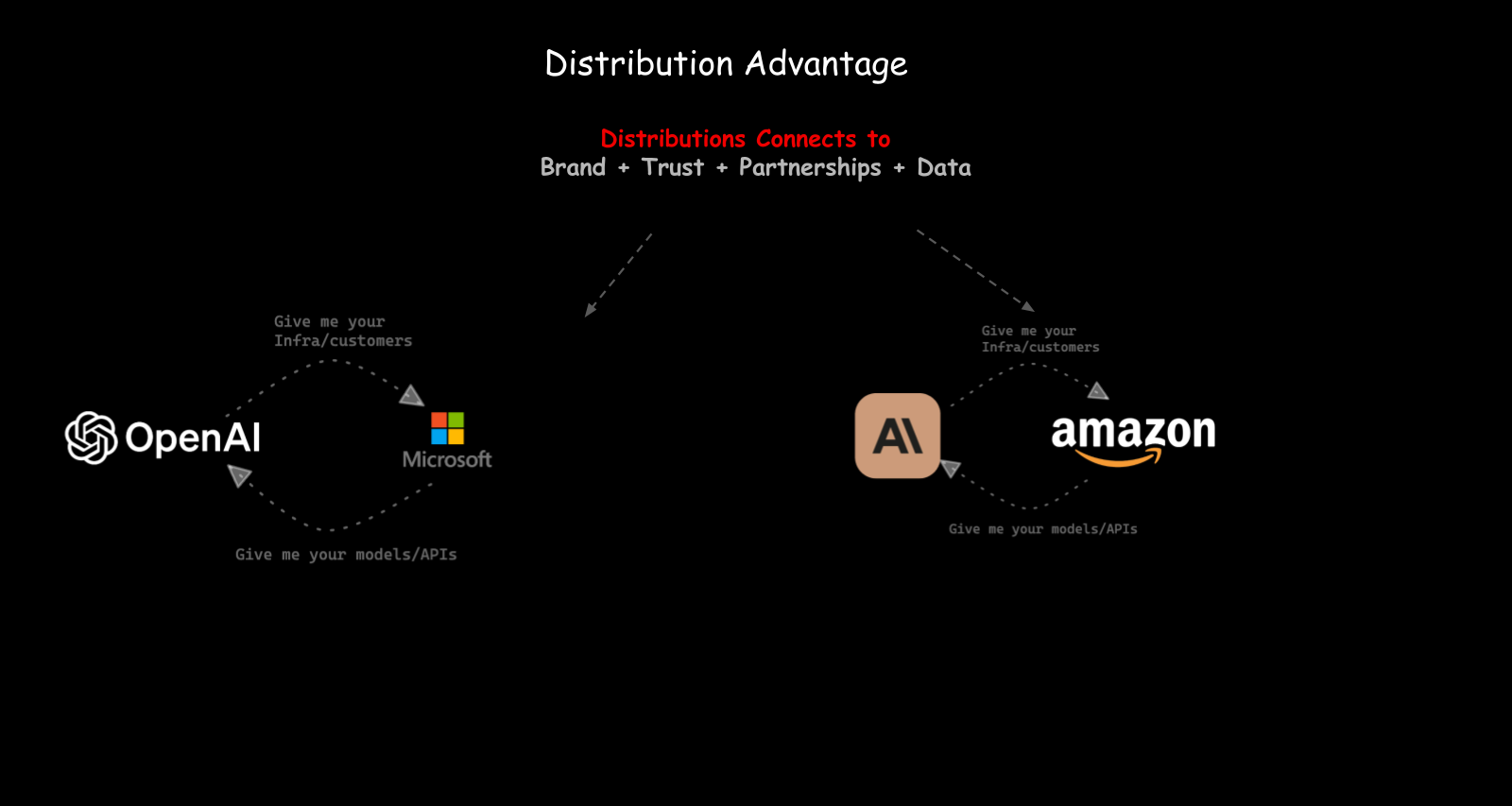
Distribution advantage — How you get your product to customers matters. ChatGPT is on people’s phones. That’s a distribution channel. That’s why Claude released a mobile app. Every AI vendor will have one, because mobile is a new distribution layer, and whoever controls the entry point controls the relationship with the user.
Compound Moats
Individual moats are useful but fragile. What really works is stacking them.
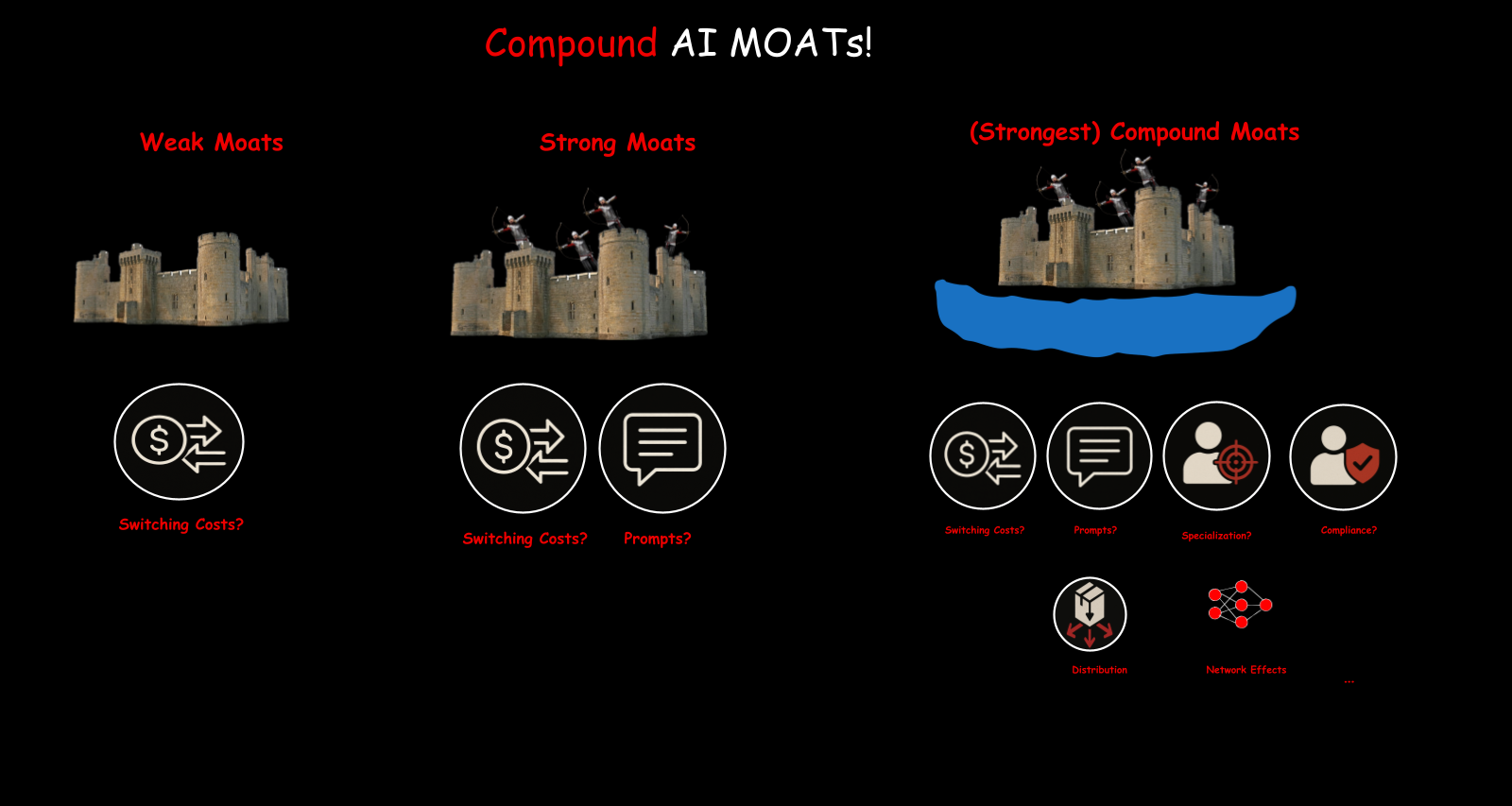
Switching costs alone are a weak moat. Compliance alone is a weak moat. Prompts and prompt libraries alone are a weak moat. But combine switching costs with compliance requirements with specialized data with network effects with distribution, and you get a compound moat. Much harder to break through.
The more dimensions of defensibility you stack, the more durable your position becomes.

Harness engineering as a moat deserves its own mention here. In Part 2, we introduced the harness as the orchestration layer that turns enablers into a working system. It has a builder side (what ships with the tool) and a user side (what your team builds on top). Both accumulate value over time.
Not all harness components are equally defensible. Some are commodity: the basic agent loop, tool call parsing, credential scrubbing. Every agent reimplements these, and they work roughly the same way everywhere. The moat lives in the model-sensitive and use-case-specific components: the system prompts tuned through hundreds of iterations, the orchestration policies shaped by domain expertise, the tool configurations built around your customers’ workflows. Those are the pieces a competitor cannot replicate by reading a blog post.
On the builder side: Meta acquired Manus for roughly $2B, not for the model (Manus uses foundation models from Anthropic and OpenAI) but for the harness. Manus rebuilt their agent harness five times in six months, each iteration improving reliability and task completion. The harness was the asset.
On the user side: every AGENTS.md rule, every custom linter, every test suite tuned to produce LLM-readable errors is an investment that compounds. A team that has spent months engineering their harness has built something a competitor cannot replicate by switching models.
Anthropic’s engineering blog puts it well: “When a new model lands, re-examine the harness, stripping away pieces that are no longer load-bearing and adding new ones. The space of interesting harness combinations does not shrink as models improve. It moves.” The harness co-evolves with the model: useful patterns get discovered, some get absorbed into the next model generation, new capabilities enable new harness designs, and the cycle repeats. It is a permanent discipline, not a transitional one.
Consider what OpenAI’s internal team pulled off: starting from an empty repository, they built roughly one million lines of production software over five months, orchestrated entirely through their Codex agent across approximately 1,500 pull requests. The model alone could not have sustained that kind of coherent output. The harness made it possible. That makes it a durable moat.
Case Studies
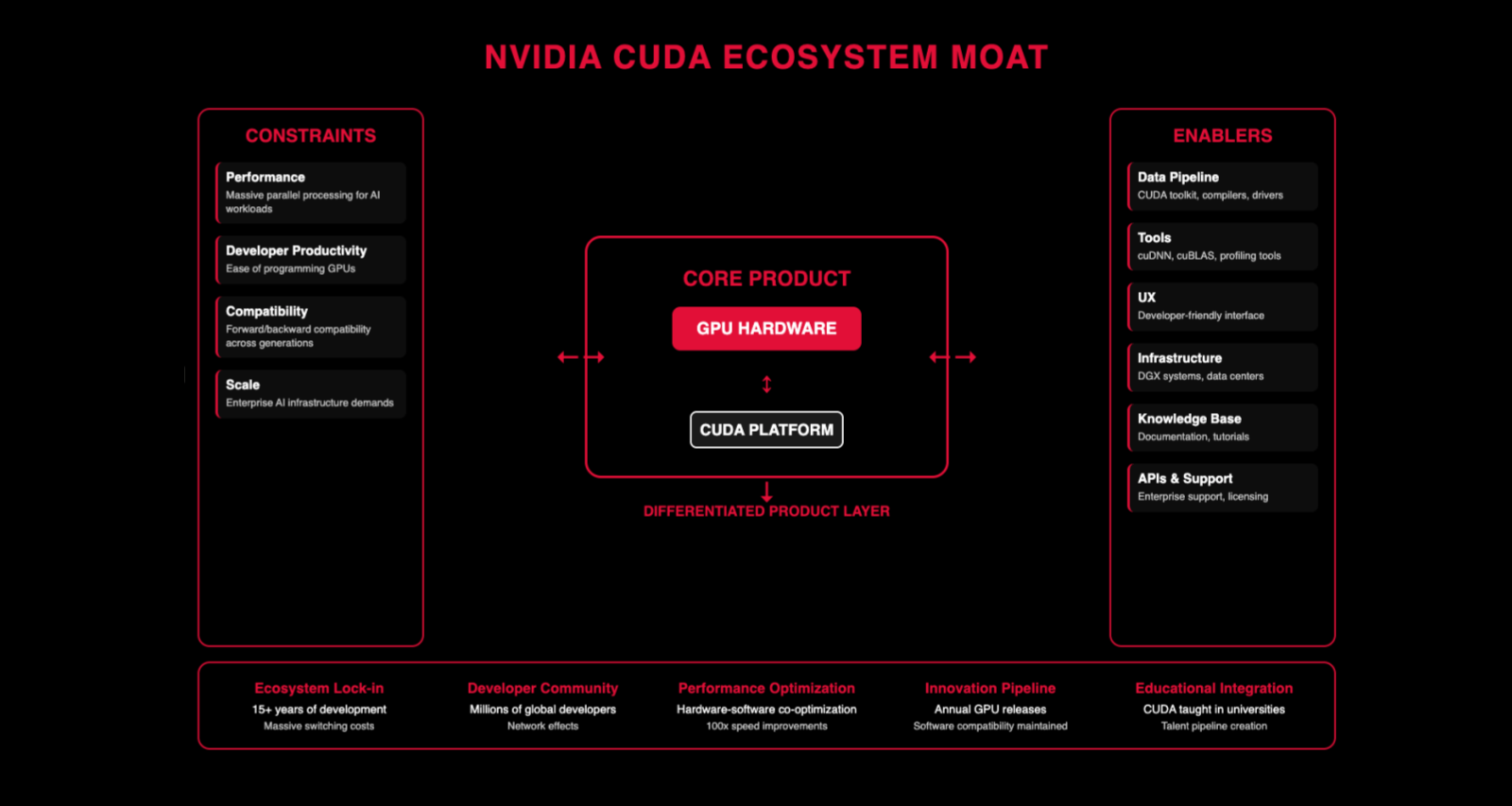
NVIDIA — Core product is GPUs and hardware. Their market cap crossed $3 trillion in 2024, making them one of the most valuable companies on the planet. CUDA is the platform layer — it’s what you need to train and run most AI workloads today, with over 4 million developers in the ecosystem, which created a near-lock-in. The H100 and B200 GPUs dominate AI training workloads. Their moat is that developer community, the performance optimization stack, and the fact that there’s no good alternative yet. Everyone has enablers (data pipelines, infrastructure, UX). What matters is the differentiators on top.
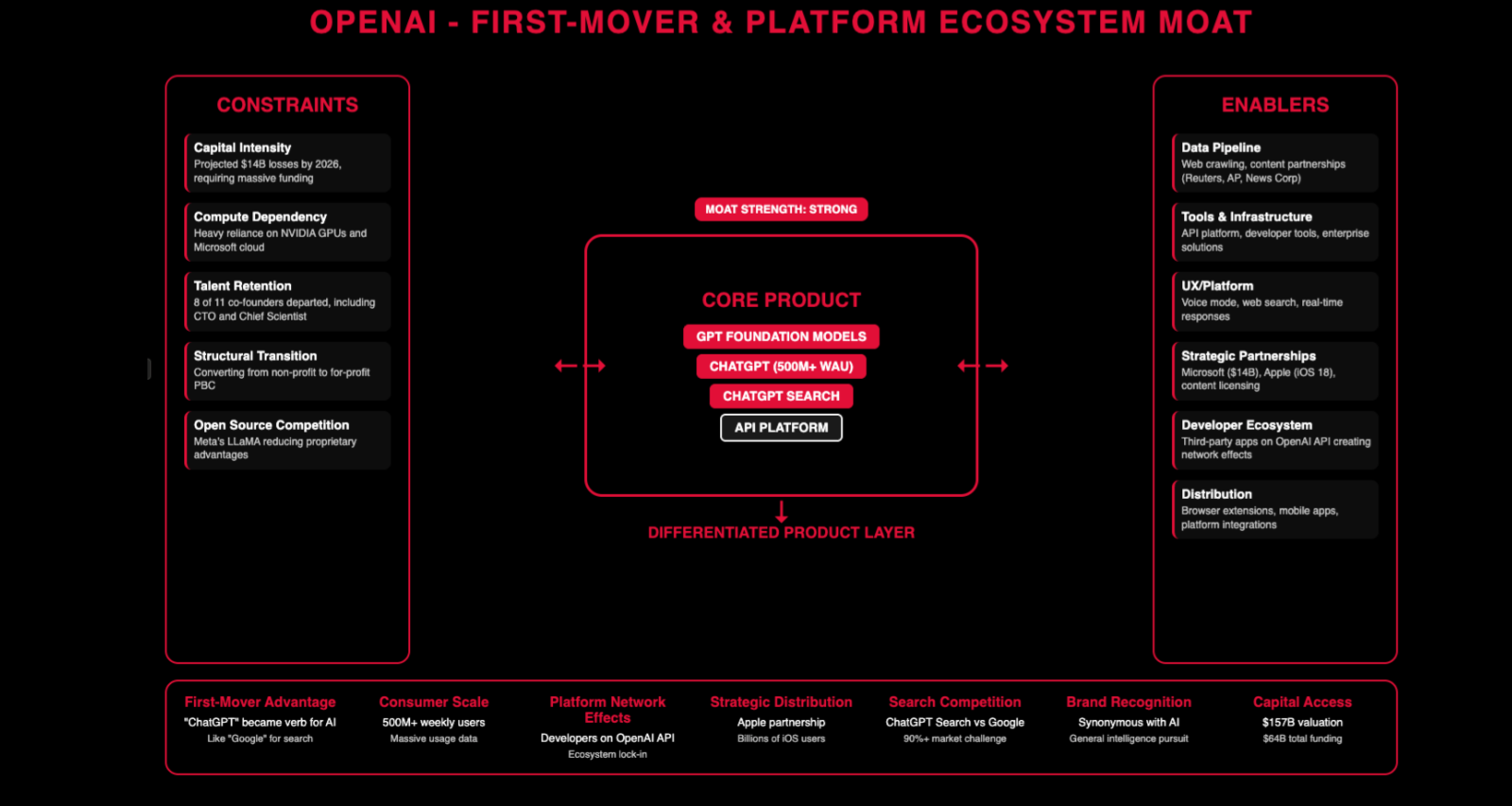
OpenAI — First mover advantage with ChatGPT, which reached 100 million weekly active users by early 2025. They raised $6.6 billion in October 2024 at a $157 billion valuation — that’s the scale of conviction behind them. Distribution through mobile changed the game — once you’re on people’s phones, you have a direct channel. They won the API battle early with Chat Completions, and they’re trying to keep that lead with the Responses API.
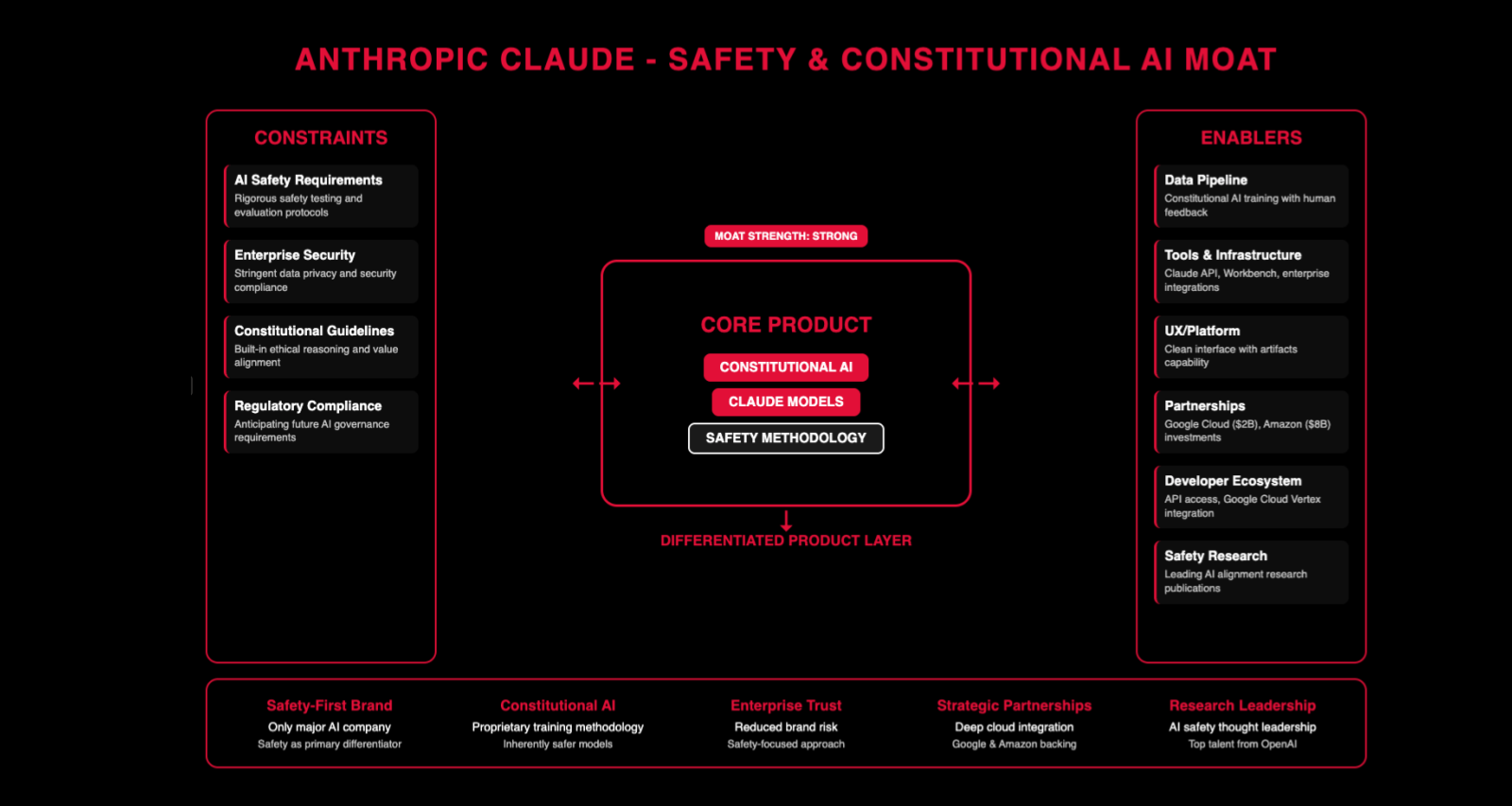
Anthropic — They didn’t have first mover advantage, so they play a different game. They raised $2 billion from Google in 2023 and secured $4 billion total from Amazon, giving them both capital and distribution channels. Constitutional AI, safety-first branding, enterprise trust through those strategic partnerships. Claude 3.5 Sonnet became widely adopted in 2024, carving out a reputation for reliability in coding and analysis. They have the same enablers as everyone else but different differentiators. Every company has to find what their moat is made of.
Notice the pattern: the enablers are roughly the same for everyone. Data pipelines, infrastructure, developer tools, UX. What differs is the differentiators. That’s what you need to think about when building AI products.
The Value Lifecycle
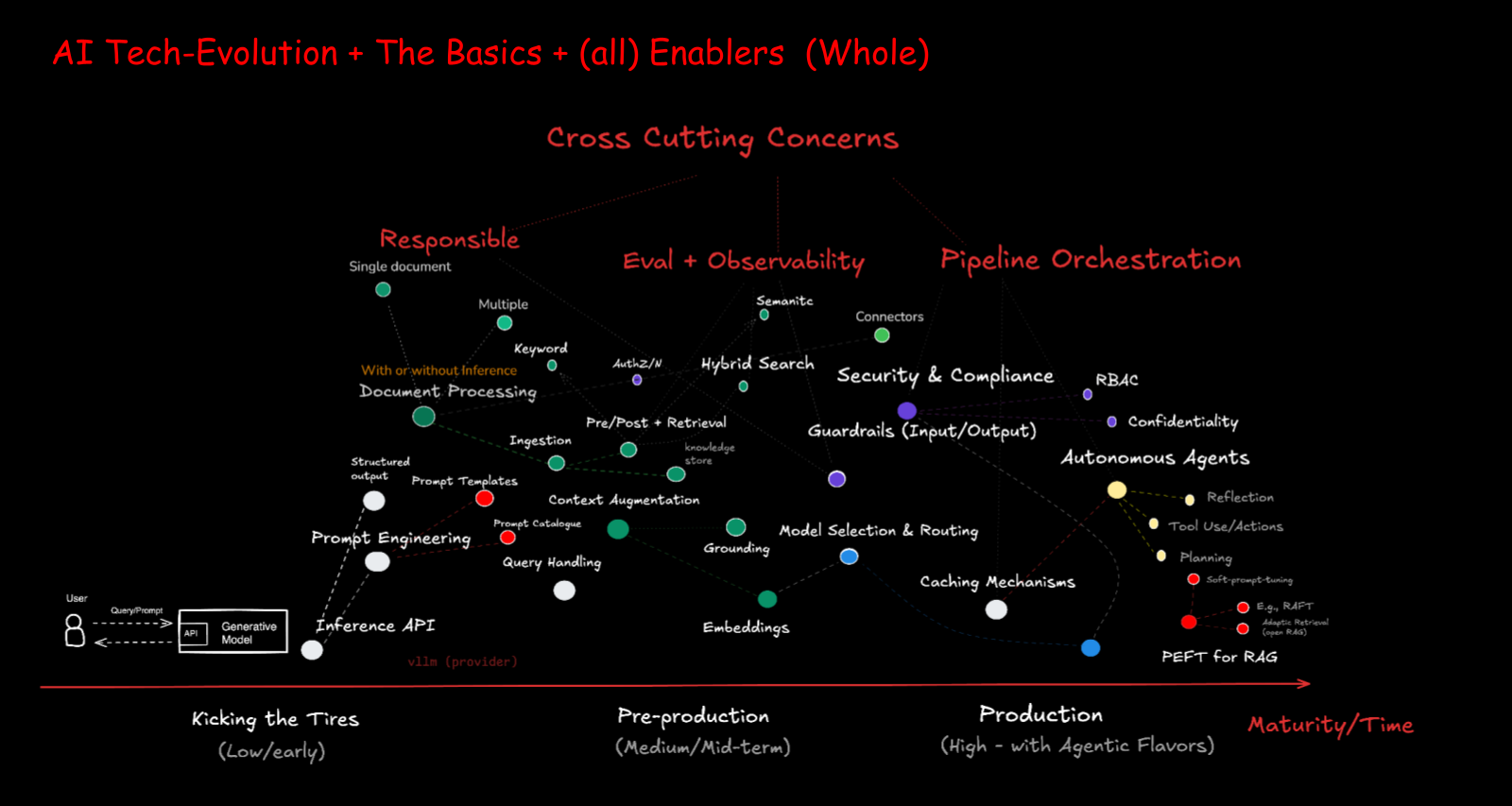
Tying it all together: the AI product evolution follows a recognizable pattern.
You start with the core technology — the models. That’s the left side of the cycle. Models alone are enough for innovators and researchers.
Add the expected product — data pipelines, retrieval, tools, basic ops. Now early adopters can use it. ChatGPT is a system, not just a model. The system is what made it usable.
Add activities — QE, testing, security audits, legal compliance, customer support. Now you’re reaching the early majority, the established companies that need SLAs and accountability. The challenge is that human verification bandwidth doesn’t scale at the same rate as generation — so tooling and process matter enormously here.
Add differentiation — the moats, the specialized workflows, the unique data advantages. That’s how you reach the late majority and build something durable.
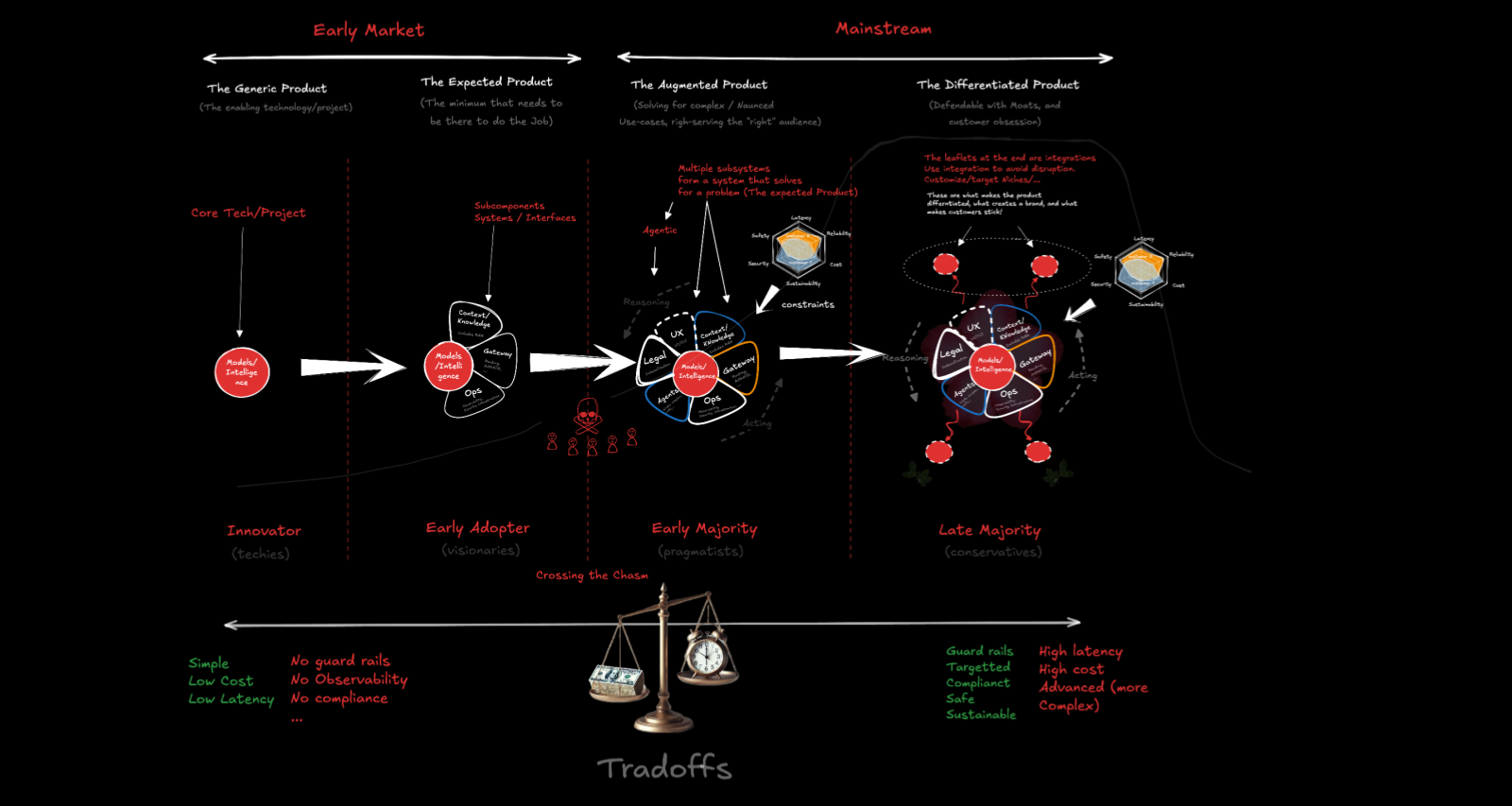
This cycle is still in its early stages. Most AI products today are somewhere between the innovator and early adopter phase. The infrastructure for the early majority — evaluation, safety, production-grade tooling — is being built right now. The companies that get this right will define the next era.
One More Thing
A question worth considering: are we heading toward a “Kubernetes moment” for AI — a standardization layer that prevents monopolization and enables interoperability?
Open source models are one such layer. The APIs are beginning to standardize — OpenAI published the Open Responses spec in 2025 as an open specification for anyone to implement. Linux Foundation AI published the Model Openness Framework in 2024, and there’s the Responsible AI framework describing how to keep things accessible.
But businesses still have to build. Standards create the floor, not the ceiling. On top of the standards, you differentiate. On top of the open model, you add your data, your workflows, your constraints. The standard prevents lock-in. The differentiation generates revenue.
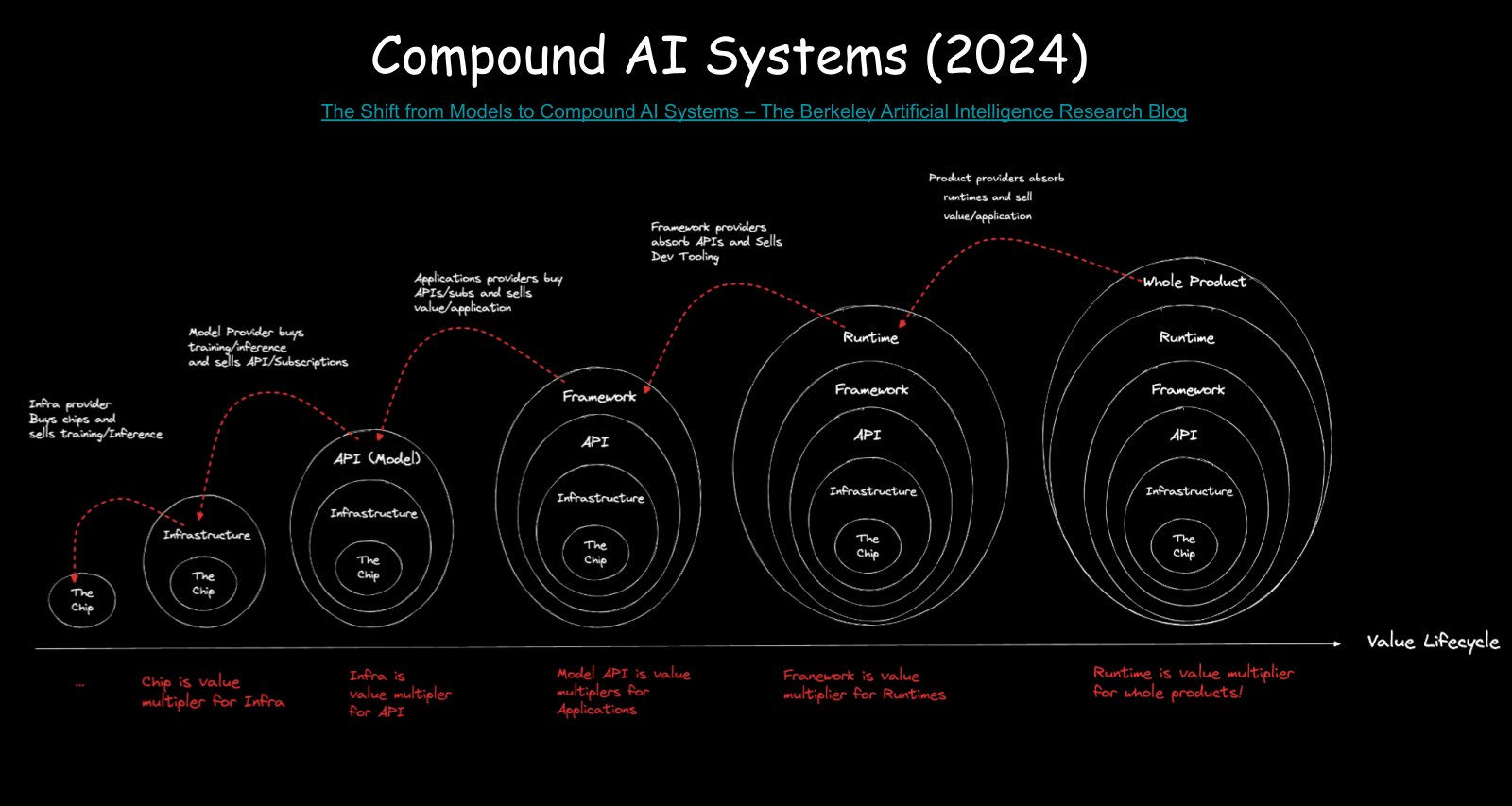
That’s the whole picture. Start with the model. Build the compound system. Apply constraints for your customers. Stack your moats. Ship the whole product.
This post is part of a presentation series — slides and related materials are on the Presentations page.